IDEA的扩展功能
之前每次我们想要去修改集群中的一些配置文件,采用的方式是vim,这种方式对于非常熟悉vim命令的程序员来说是很方便的,但是对于我们大多数初学者很不友好。前面我们使用过IDEA去编写Java代码,这种方式十分高效,那么如果可以使用IDEA去直接修改配置文件,那我们代码的编写效率就可以大大提升了。
在IDEA中是有这样的功能的,接下来我们一起操作。
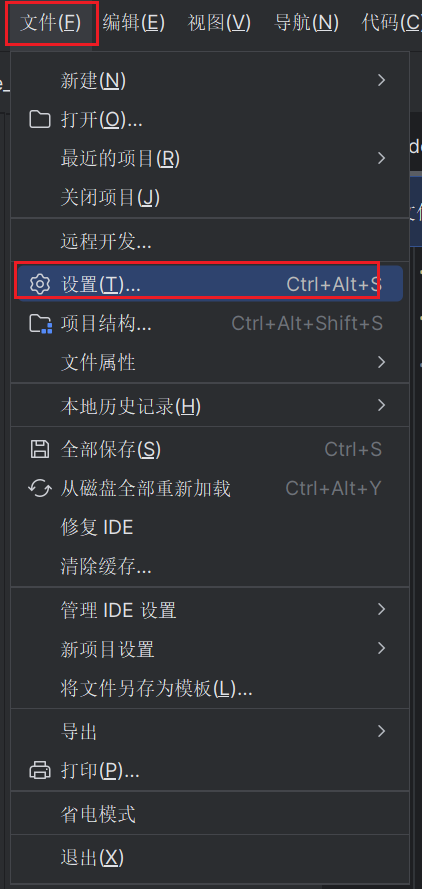
依次点击工具->部署->浏览远程主机
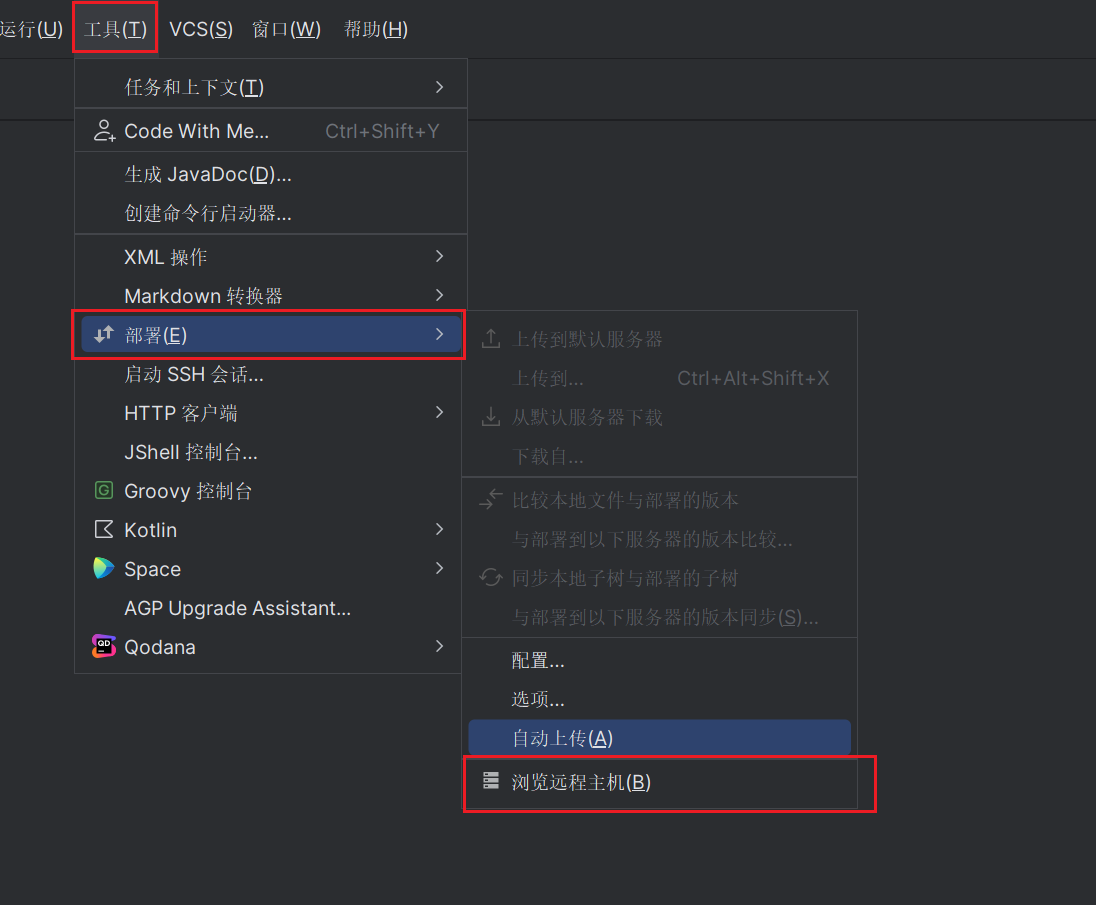
这个时候会弹出以下界面,比如我们想要连接hadoop102,我们可以在其中填写以下内容:
- 名称:
hadoop102 - 类型:
SFTP
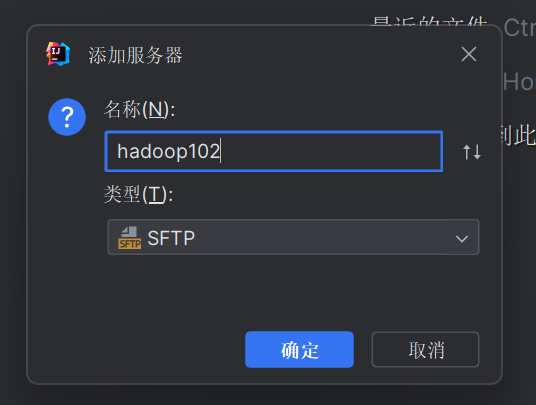
接下来点击图示中的...选择SSH配置。
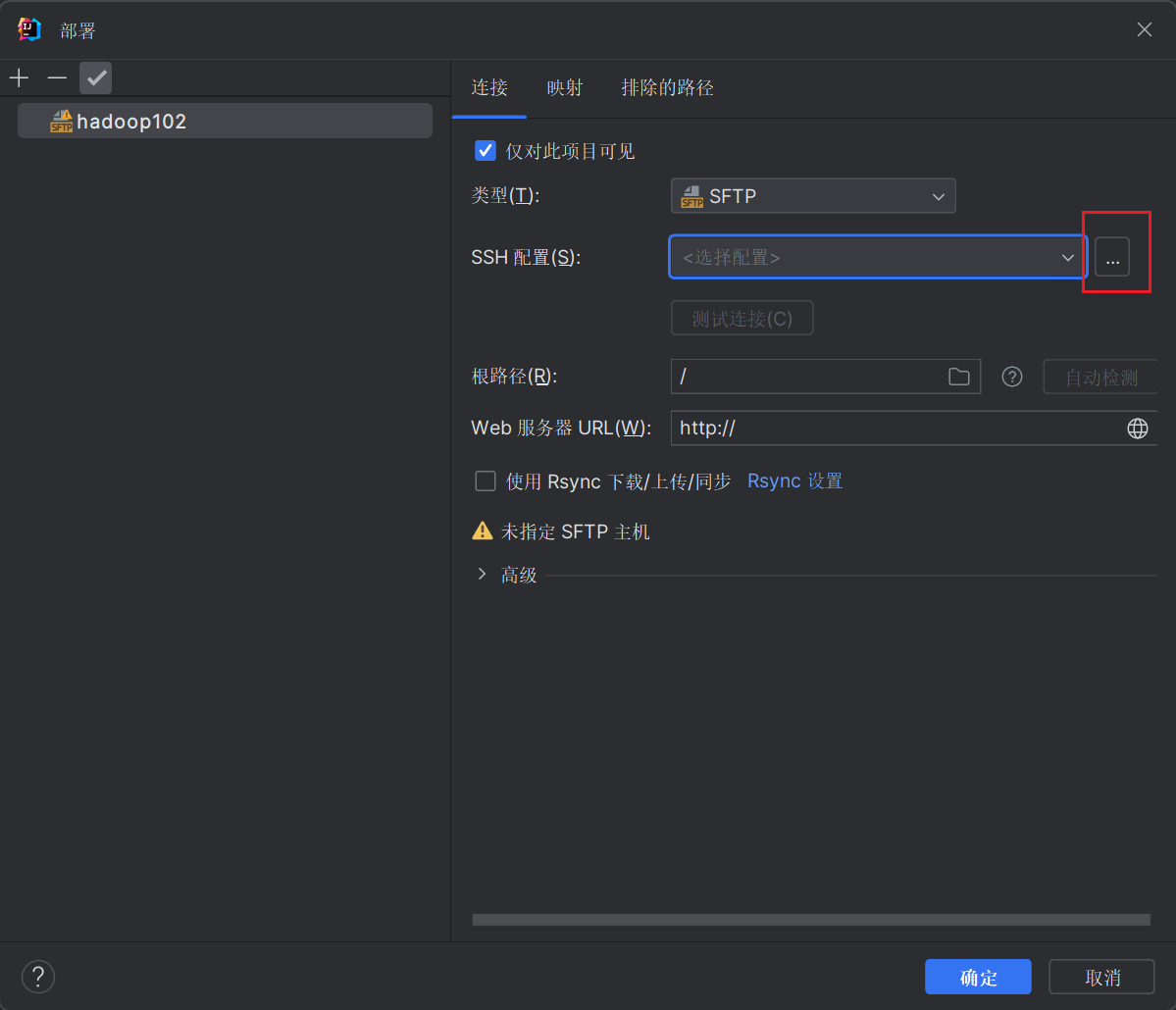
此时点击+去添加一个SSH配置,然后填入hadoop102的SSH登录信息。
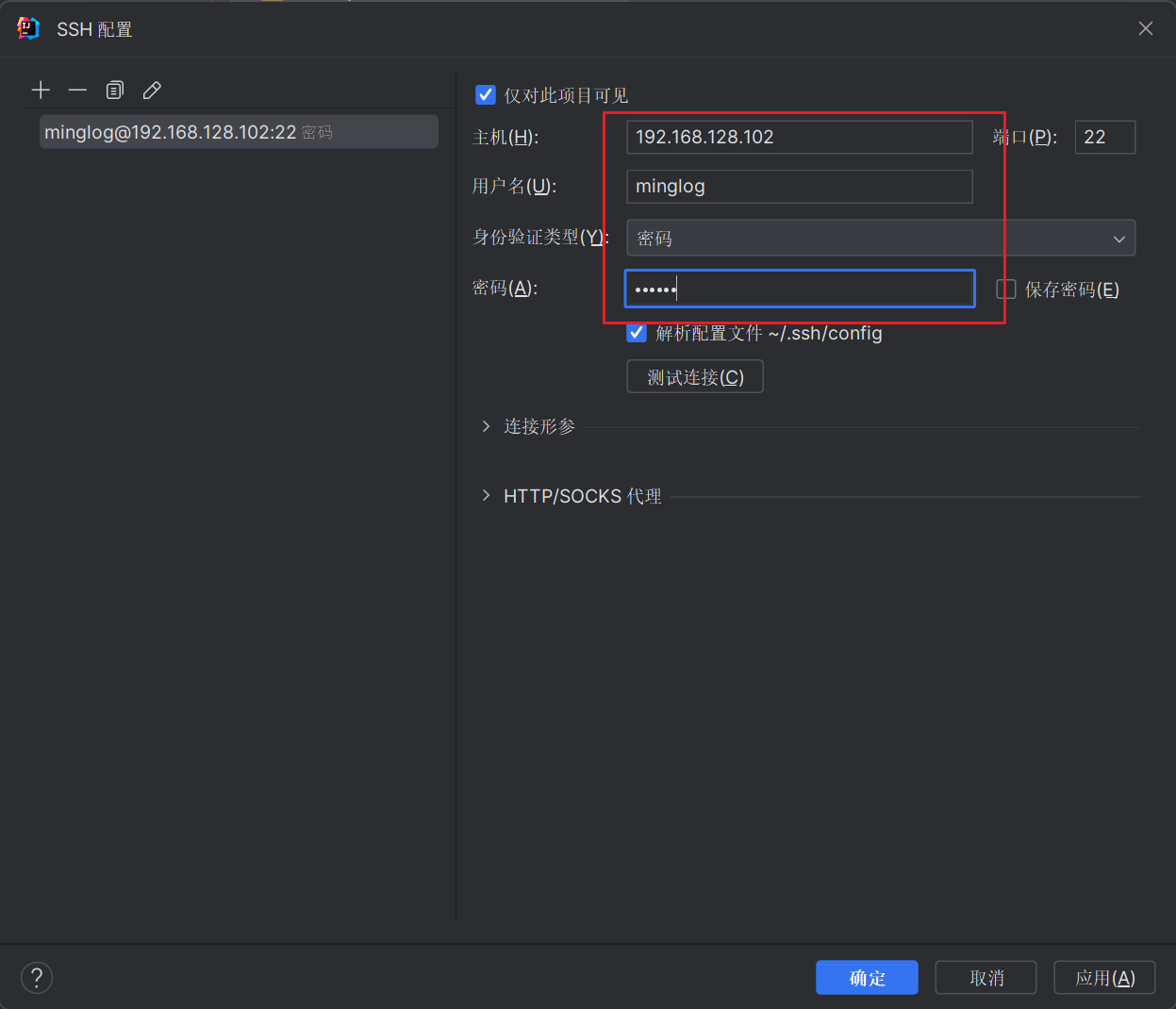
填写完毕后,点击测试连接。
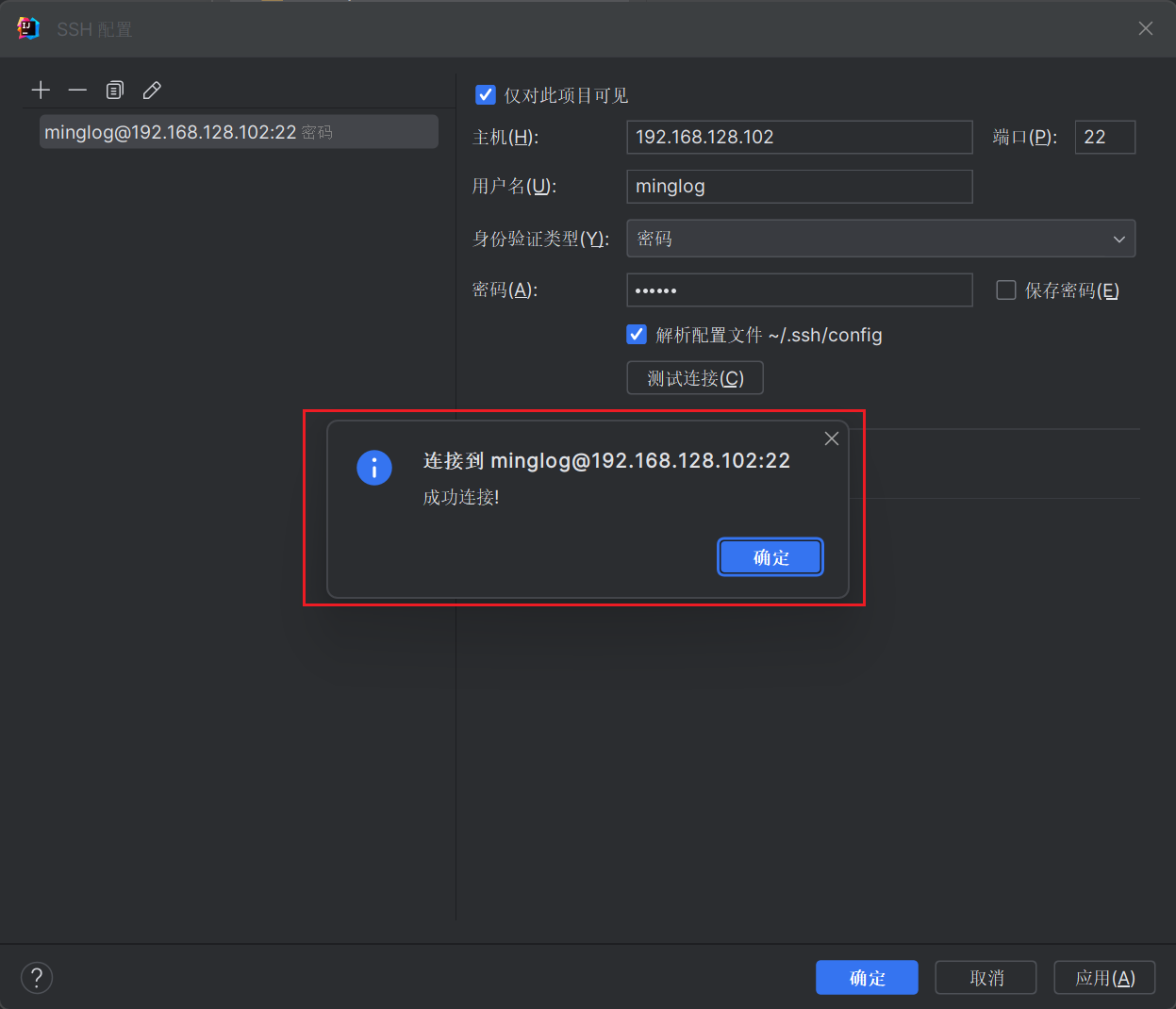
显示成功连接就说明SSH连接是正常的,接下来每个页面中都点击确定。
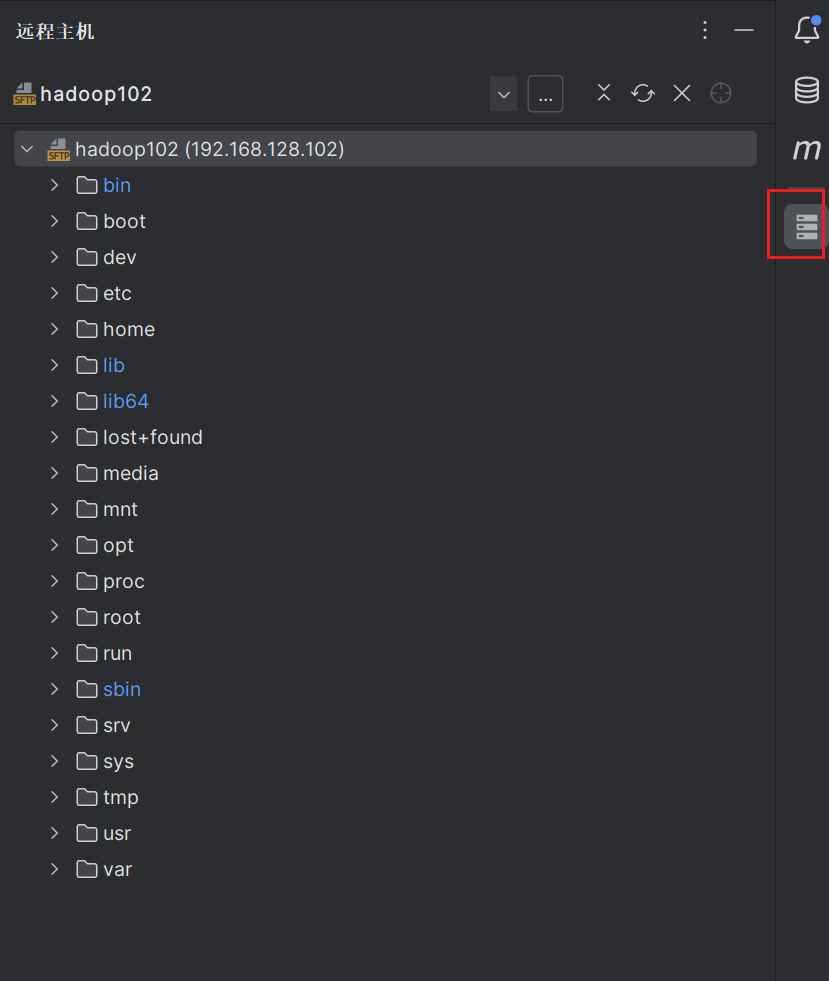
这个时候在右侧的侧边栏中就会多出一个选项,点击该选项后就可以查看远程的主机文件信息。
我们可以直接在该界面中操作远程服务器的文件系统,比如去修改配置文件获取是上传文件,都十分方便。
例如我们点击之前在hadoop中的配置文件core-site.xml。
双击打开文件。
打开完毕后,会在当前本地的IDEA中打开配置文件。
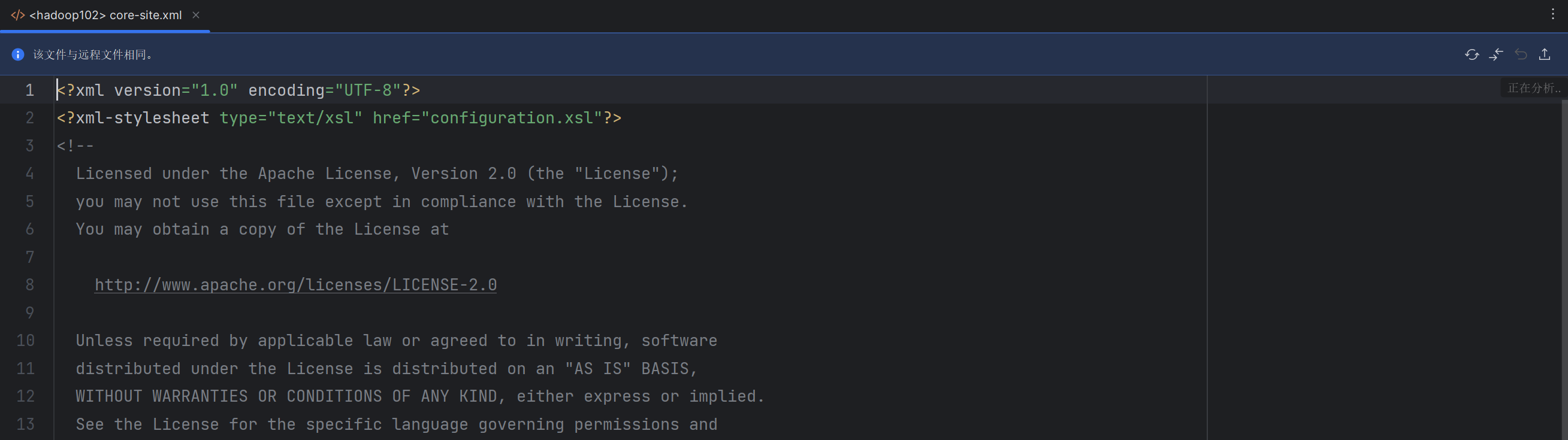
并且在文件上方会显示当前文件与远程文件是否存在差异,如果我们修改了就是存在差异,会提示我们文件已修改,是否上传到远程主机进行修改,我们想要远程文件同步修改就必须点击上传按钮进行同步。

点击同步按钮后,就又会恢复到与远程文件相同的提示。

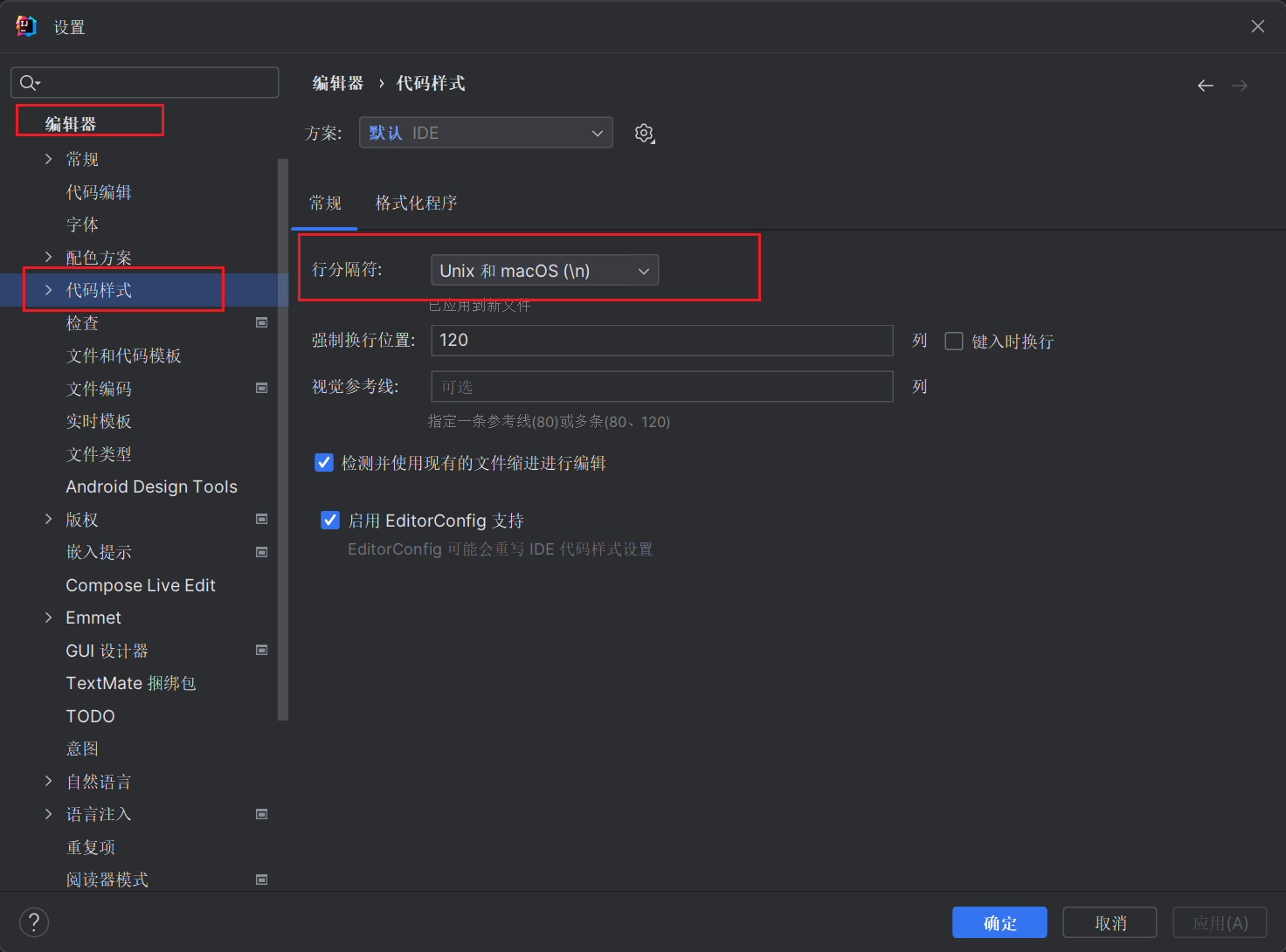
还需要注意一个文件,就是在
Windows系统中和Linux系统中,对于文件中的换行符是存在差异的。
Windows:\r\n。Linux:\n。我们想要在编写相关文件能够在远程的
Linux主机中运行,还需要去修改使用IDEA编写代码是,换行符采用\n。依次点击
文件->设置
然后找到
编辑器->代码样式->行分隔符,修改为Unix 和 macOS(\n)
Hive基本概念
Hive的产生背景
现在我们有了HDFS来存储海量数据、MapReduce来对海量数据进行分布式并行计算、Yarn来实现资源管理和作业调度。但是面对海量数据和负责的业务逻辑,开发人员要编写MR来对数据进行统计分析难度极大、效率较低,并且对开发者的Java功底也有要求。所以Facebook公司在处理自己的海量数据时开发了hive这个数仓工具。Hive可以帮助开发人员来做完成这些苦活(将SQL语句转化为MapReduce在yarn上跑),如此开发人员就可以更加专注于业务需求了。
Hive简介
Hive是由Facebook开源用于解决海量结构化日志的数据统计工具。Hive是基于Hadoop的一个数据仓库工具,将结构化的数据文件映射为一张表,并提供类SQL(HQL)查询功能。
映射成为一张表,实际上并没有这个表。
Hive的本质
Hive的本质实际上就是将复杂的MR程序转化成为了简单的HQL程序语句。
Hive其实就是做的一个翻译工作,将HQL语句翻译为MR程序,然后在集群下执行任务。
Hive架构基本原理
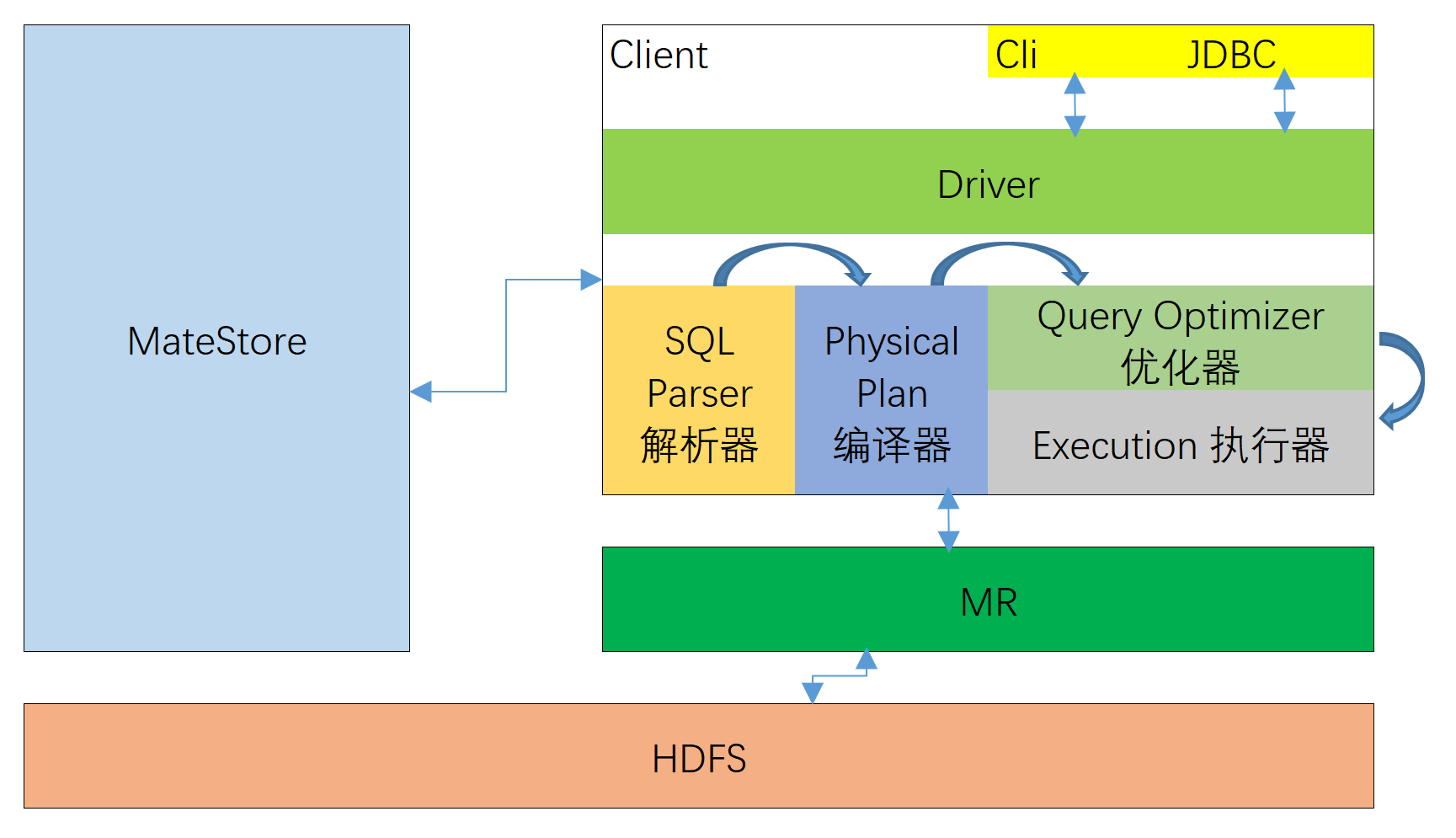
整个框架的基本原理如图所示,其中涉及到的一些组件功能如下图所示。
MateStore:指的是创建出来的元数据。前面讲过Hive中的数据表都是映射出来的,那么实际使用的时候究竟是如何映射的,这个时候就需要使用到元数据去映射出具体的表。
Cli和JDBC:表示连接Hive的两种方式,客户端连接和JDBC连接。
Driver:Hive驱动用于客户端与服务器之间进行数据交互,驱动器又被分为4个步骤,分别由不同的角色承担。如下所示:
SQL Parser:将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。Physical Plan:将AST编译生成逻辑执行计划。Query Optimizer:对逻辑执行计划进行优化。Execution:把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
Hive在执行HQL的整个过程如下:
- 获取客户端发送过来的
HQL代码。 - 首先由
SQL Parser去检查HQL代码是否有语法错误,如果有直接报错。如果没有语法错误,就会去生成一个抽象语法树AST。 - 那么接下来就由
Physical Plan将AST进行编译,生成逻辑执行计划。也可以说是初步的MR程序。 - 为了提高
MR程序的运行效率,Query Optimizer会去改进MR程序的执行逻辑,使得其运行起来更高效。 Execution去提交对应的MR程序到集群中去执行。
Hive和数据库比较
| Hive | mysql | |
|---|---|---|
| 语言 | 类sql |
sql |
| 数据规模 | 大数据pb及以上 |
数据量小一般百万左右到达单表极限 |
| 数据插入 | 能增加insert,不能update,delete |
能insert,update,delete |
| 数据存储 | Hdfs |
拥有自己的存储空间 |
| 计算引擎 | Mapreduce/spark/tez |
自己的引擎innodb |
综上所述,Hive压根就不是数据库,Hive除了语言类似以外,存储和计算都是使用Hadoop来完成的。而Mysql则是使用自己的,拥有自己的体系。
Hive的优缺点
| 优点 | 缺点 | |
|---|---|---|
1. 提供了类SQL语法操作接口,具备快速开发的能力(简单、易上手) |
1. Hive的HQL表达能力有限 |
1)Hive自动生成MapReduce作业,通常情况下不够智能化 |
2. 避免了去写MapReduce,减少开发者的学习成本 |
2)数据挖掘方面不擅长(多个子查询),由于MapReduce数据处理流程的限制,效率更高的算法却无法实现 |
|
3. Hive优势在于处理大数据,在处理小数据时没有优势,因为Hive的执行延迟较高。 |
2. Hive的效率比较低 |
1)Hive的执行延迟比较高,因为Hive常用于数据分析,对实时性要求不高的场合 |
2)Hive调优比较困难,粒度较粗 |
||
4. Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数 |
3. Hive不支持实时查询和行级别更新 |
hive分析的数据是存储在HDFS上的,而HDFS仅支持追加写,所以在Hive中不能update和delete,只能select和insert。 |
Hive安装
修改hadoop相关参数
修改core-site.xml
1 | <!-- 配置该minglog(superUser)允许通过代理访问的主机节点 --> |
修改yarn-site.xml
1 | <!-- NodeManager使用内存数,默认8G,修改为4G内存 -->(16g物理内存的改为2g或者是3g) |
修改完后分发
1 | xsync /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml |
然后重启集群
1 | myhadoop stop |
Hive下载与解压安装
下载完后上传到/opt/software,然后解压安装包到/opt/module目录
1 | tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/ |
解压完成后,接下来给Hive设置环境变量
1 | sudo vim /etc/profile.d/my_env.sh |
添加以下内容:
1 | #HIVE_HOME |
重新启动客户端,让环境变量生效。
Hive元数据部署
元数据之Derby
内嵌模式示意图:
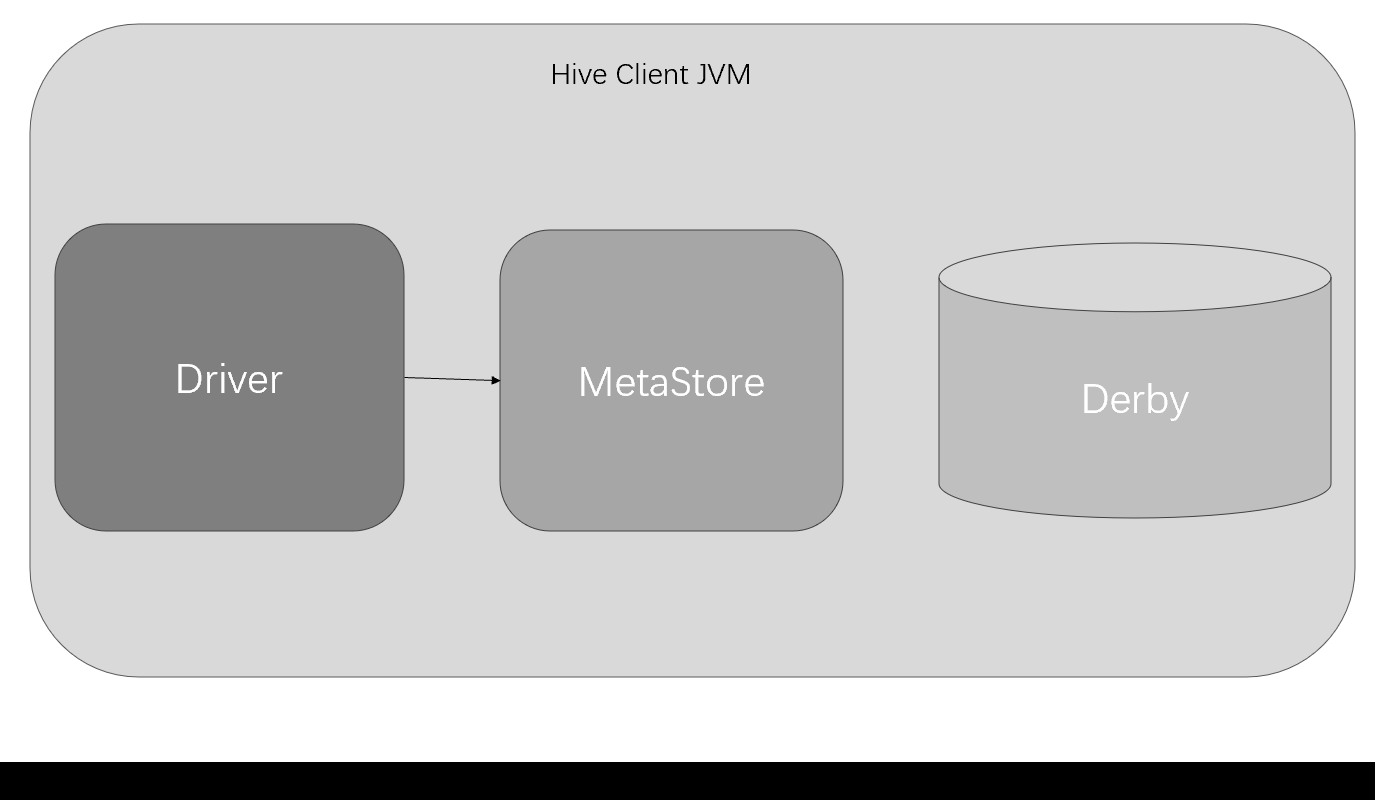
Derby数据库是Java编写的内存数据库,在内嵌模式中与应用程序共享一个JVM,应用程序负责启动和停止。
首先初始化Derby数据库,执行以下命令:
1 | schematool -dbType derby -initSchema |
执行上述初始化元数据库时,会发现存在jar包冲突问题,现象如下:
SLF4J: Found binding in [jar:file:/opt/module/hive/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
出现这个问题的原因是:
hadoop和hive下都有这个jar包.解决办法:以底层的
hadoop为主,改了hive的。
2
3
4
cd $HIVE_HOME
mv lib/log4j-slf4j-impl-2.10.0.jar lib/log4j-slf4j-impl-2.10.0.back
初始化完毕后在Hive目录下就会生成一个日志文件和一个数据库目录。
如果我们初始化失败,或者想要重新初始化
Hive都需要将这两个文件删除再重新初始化。
接下来执行以下命令,即可启动hive,并通过Cli方式连接到hive。
1 | hive |
启动
hive时会出现以下的一行提示信息。
该提示信息大致意思是我们没有启动
hbase服务,这个暂时不管,后续我们讲完hbase的时候就不会出现了。

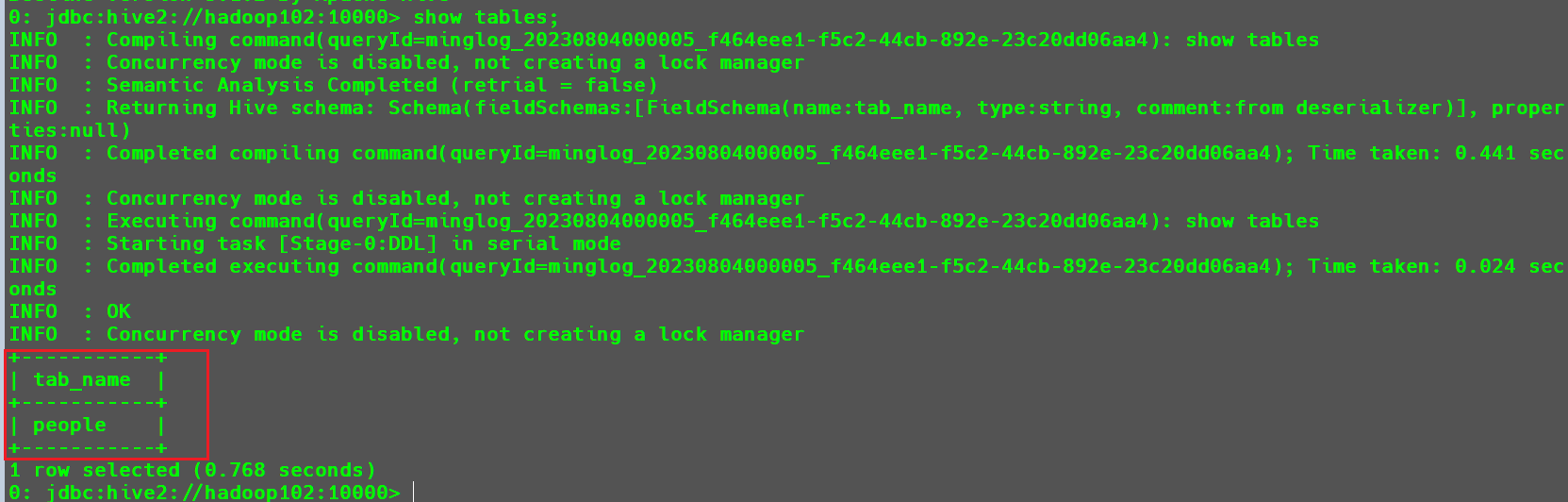
这个时候我们就可以输入相关的SQL命令去操作Hive了。
例如:
- 查看当前数据库,并创建一个
people数据表
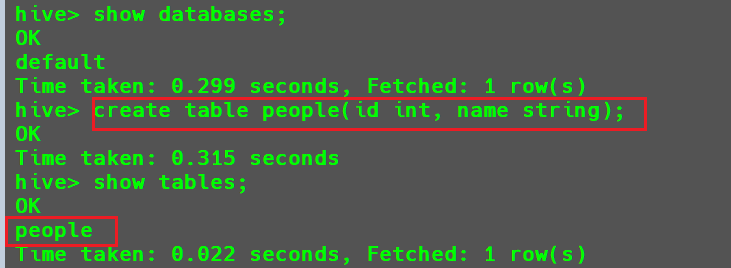
然后向该表中插入两条数据。
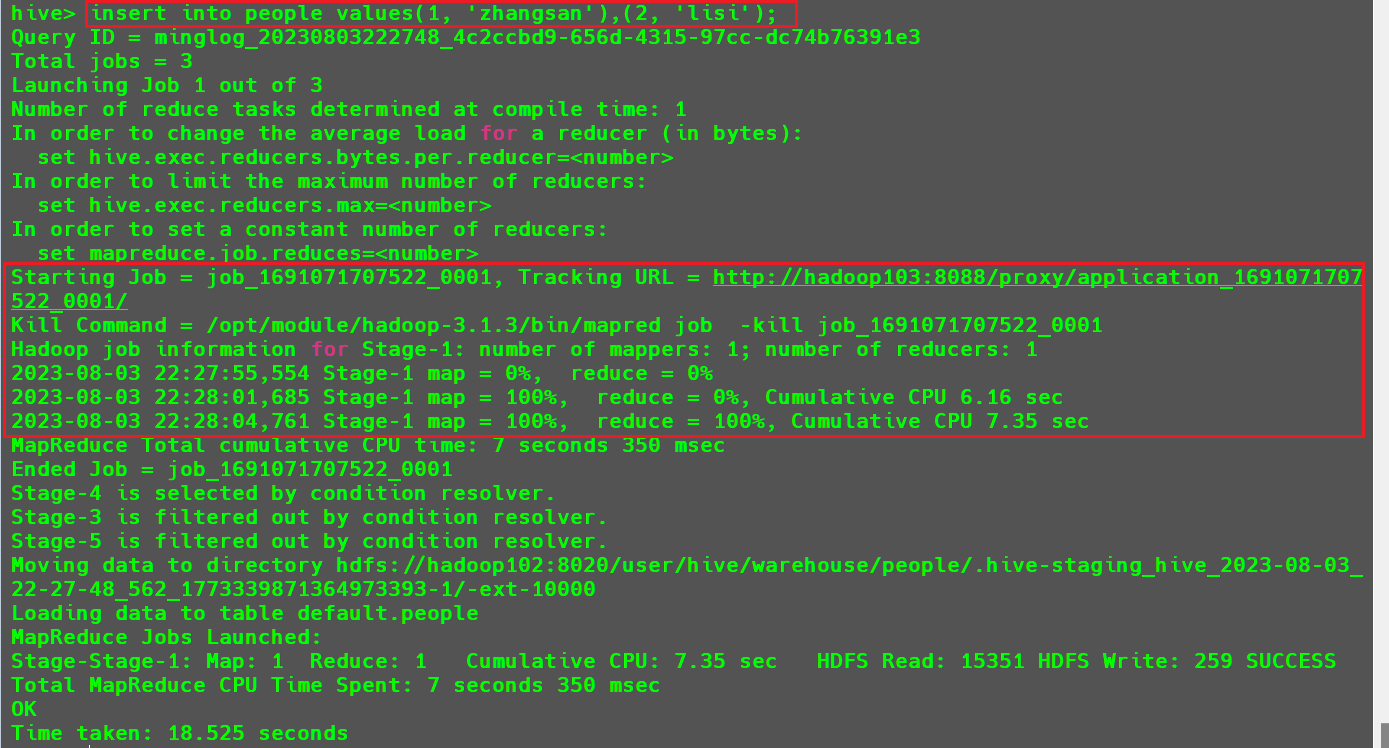
可以看到此时其实就是执行的是一个
MR任务。并且此时在
HDFS中也会存储该文件。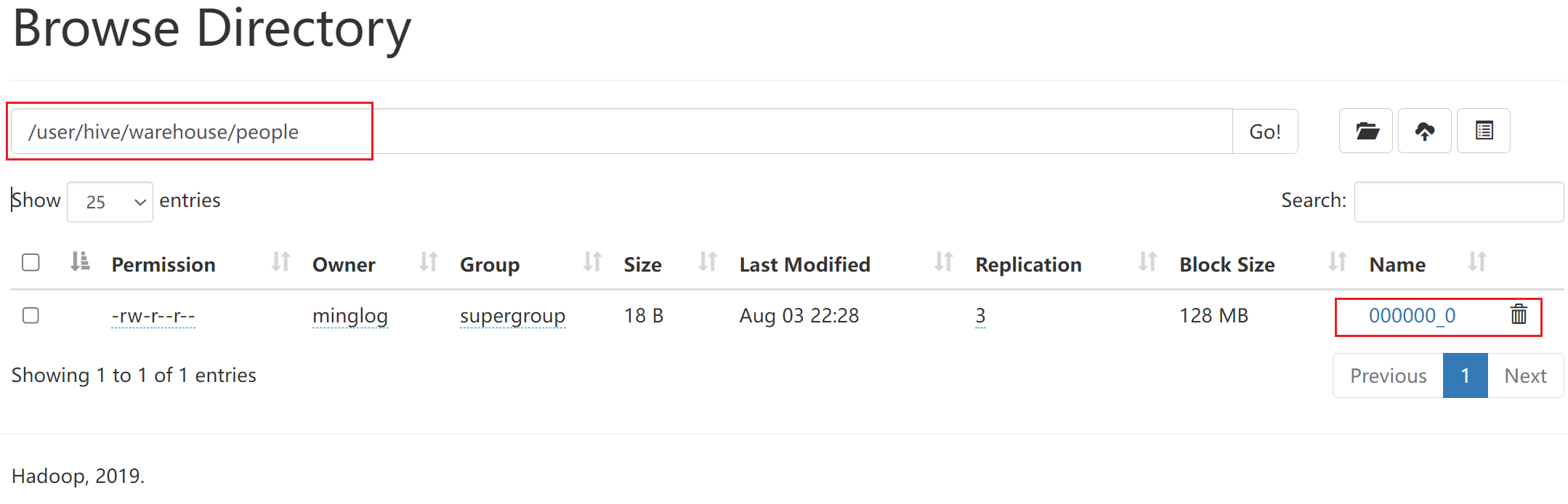
在内嵌模式下只有一个JVM进程。
这个时候再打开一个hadoop102的SSH窗口,输入jps。
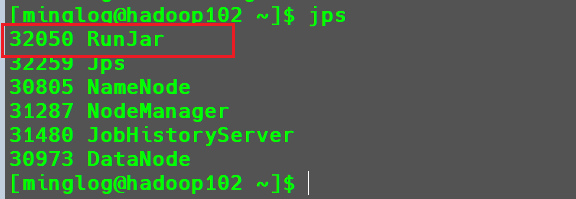
可以看到多出了一个RunJar进程,但是无法看到具体的任务是什么。
可以输入-ml参数,展示对于进程的全类名。
1 | jps -ml |

这个时候就可以看到,RunJar进程就是CliDriver进程,也就是Hive的客户端进程。就是我们另外一个没有关闭的Hive终端。
在该终端下输入hive也进入到hive客户端。
在该终端下输入show databases;展示数据库,发现出现报错。

出现错误的原因是因为Hive默认使用的元数据库为derby并且部署方式是内嵌式,在开启Hive之后就会独占元数据库,且不与其他客户端共享数据,如果想多窗口操作就会报错,操作比较局限。为此Hive支持采用MySQL作为元数据库,就可以支持多窗口操作。
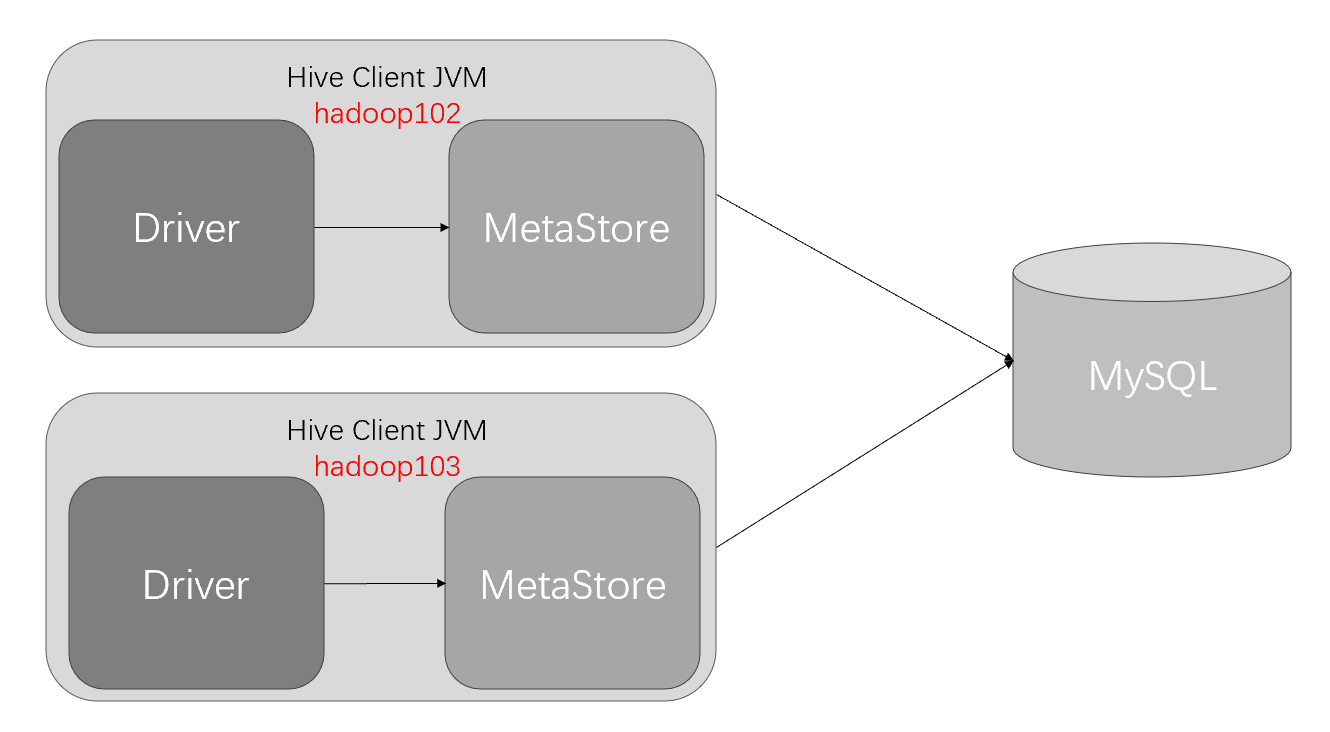
元数据之mysql
直连式示意图:
Mysql安装部署
首先检查当前系统是否安装过Mysql,如果存在就是用下列命令移除,如果不存在则忽略。(一定要做这一步)
1 | rpm -qa|grep mariadb # 如果有返回内容说明存在数据库 |
将MySQL安装包和驱动包上传到/opt/software目录下。
然后在/opt/software下新创建mysql_jars目录
1 | mkdir /opt/software/mysql_jars |
解压MySQL安装包资源到/opt/software下新创建的mysql_jars目录
1 | tar -xf /opt/software/mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar -C /opt/software/mysql_jars |
进入到mysql_jars就可以看到解压后的文件如下图所示。
接下来在mysql_jars目录下执行以下代码进行安装:
1 | sudo rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm |
在安装最后一条命令时可能出现以下报错。
出现这个错误的原因是因为我们采用的是最小化安装,有部分依赖没有安装完成。
采用以下命令安装解决后继续安装最后一个包。
2
3
sudo rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm

如果在mysql的数据存储路径下有文件存在,需要将其全部删除,存储路径地址在/etc/my.cnf文件中datadir参数所对应的值:
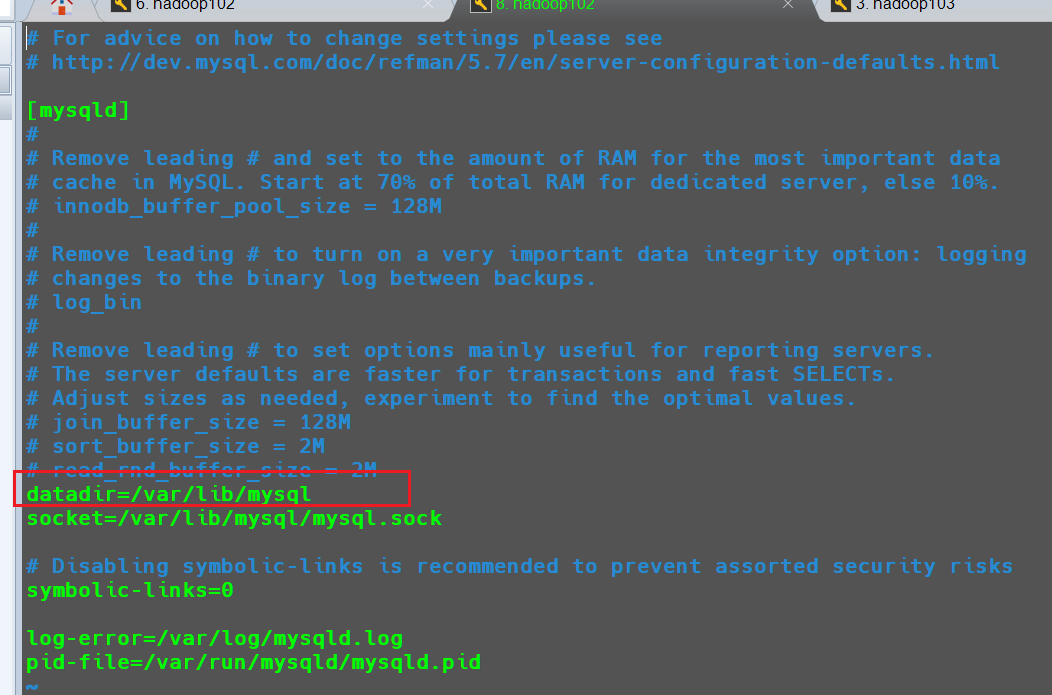
1 | sudo rm -rf /var/lib/mysql/* |
接下来初始化mysql数据库,会创建mysql内部数据库、表及初始化密码。
1 | sudo mysqld --initialize --user=mysql |
查看root用户首次登录mysql的初始密码
1 | sudo cat /var/log/mysqld.log |

此时我的初始密码就是uuSMD=wEf8!8
接下来开启mysql服务
1 | sudo systemctl start mysqld |
然后进入到mysql数据库
1 | mysql -uroot -p |
执行完成后输入上方的初始密码进入mysql。
这个时候是不能够执行SQL命令的。

提示我们需要修改初始密码,才可以操作数据库。
将初始密码修改为123456
1 | set password = password("123456"); |
默认情况下Mysql的登录权限之开启了root用户在本机登录。我们想要在其他节点下去使用Mysql就必须设置允许用户在任意节点访问数据库。
1 | update mysql.user set host='%' where user='root'; |
修改完成后刷新数据库配置。
1 | flush privileges; |
这样数据库的安装就完成了。
配置Hive元数据库为Mysql
首先,将Mysql的JDBC驱动拷贝到Hive的lib目录下,供Hive使用
1 | mv /opt/software/mysql-connector-java-5.1.37.jar /opt/module/hive-3.1.2/lib/ |
然后,配置Metastore到MySql,在Hive家目录下的conf目录下新建hive-site.xml文件
1 | vim /opt/module/hive-3.1.2/conf/hive-site.xml |
并在文件中加入以下配置内容。
1 |
|
接下来Hive初始化Mysql元数据库
在初始化之前首先在Mysql中创建metastore数据库。
1 | mysql -uroot -p |
输入密码后执行以下SQL命令
1 | create database metastore; |
然后初始化Hive元数据库
1 | schematool -initSchema -dbType mysql -verbose |
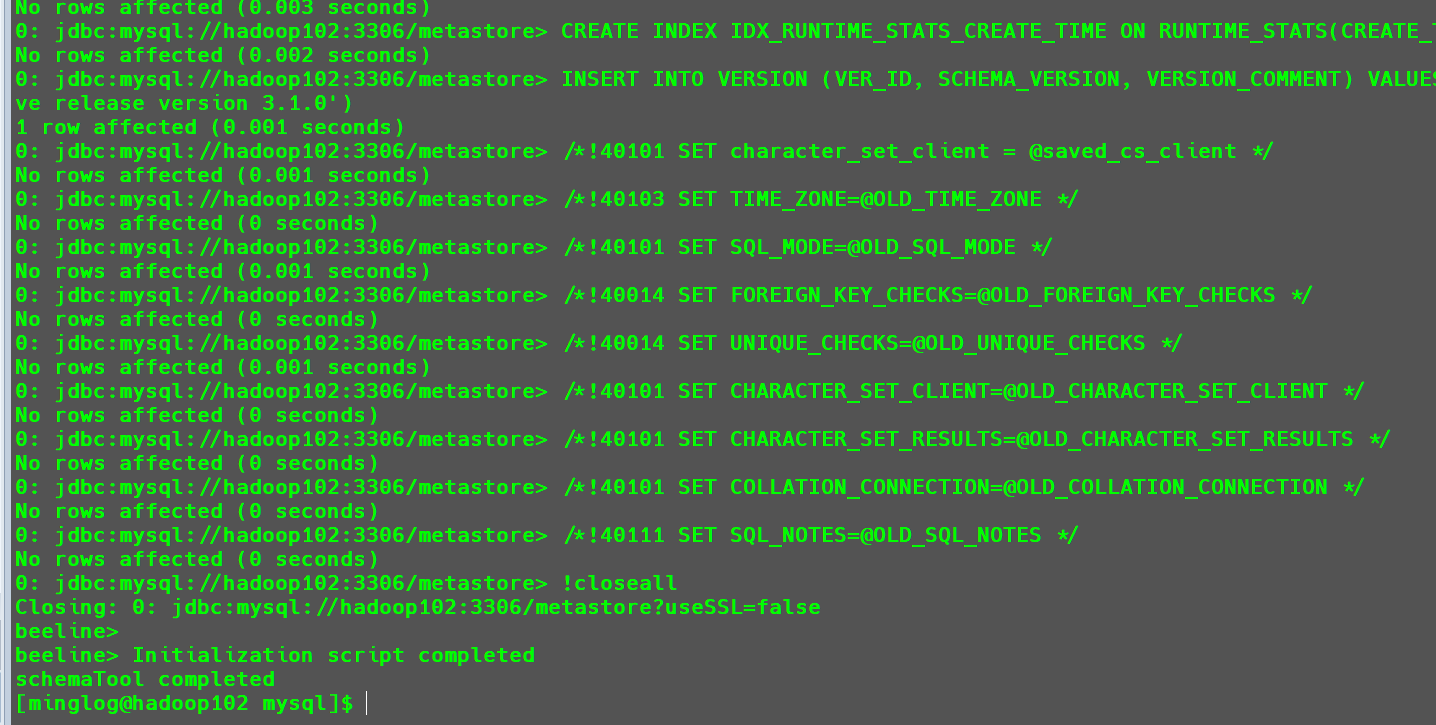
初始化完成后,会在Mysql中的metastore数据库中生成一系列的数据表,这些数据表共同组成了Hive的元数据功能。
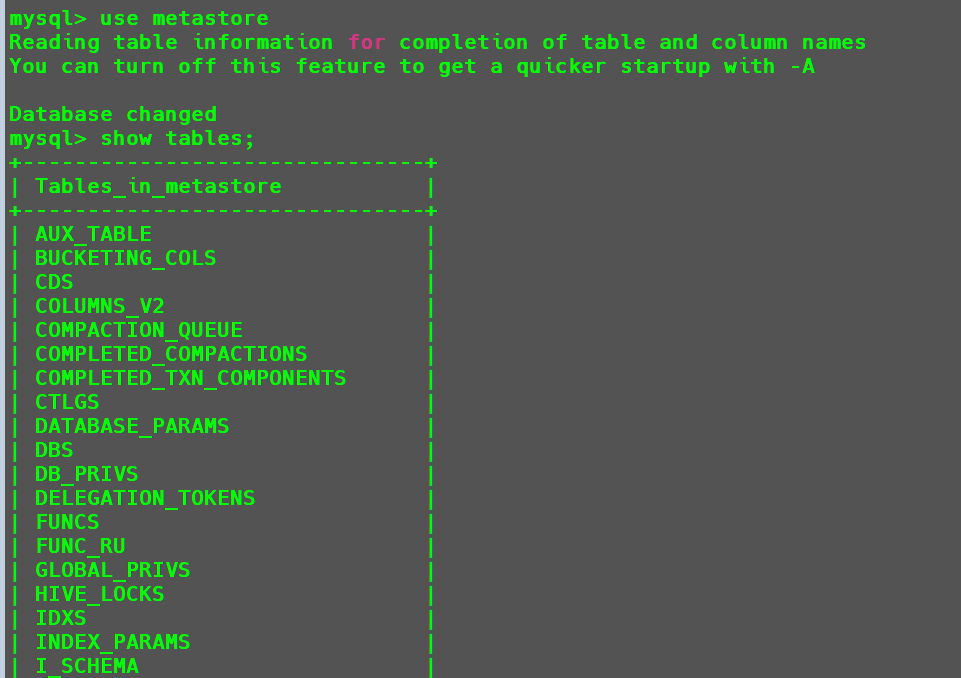
这个时候再次开启Hive
1 | hive |
使用hive执行相关命令
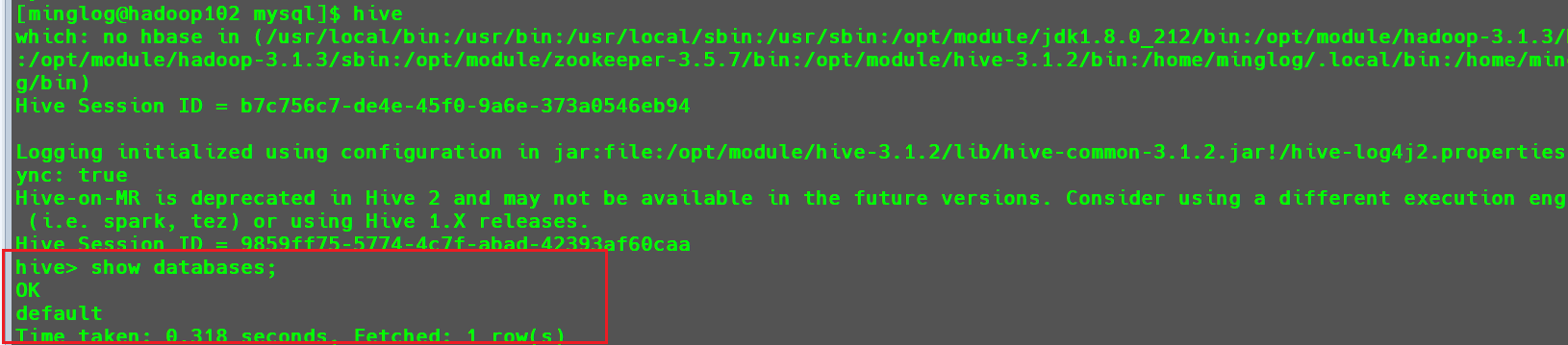
返回正常,Hive功能可以使用。
接下来再次打开一个hadoop102的SSH窗口输入hive,在该窗口的hive中再次测试hive是否可以使用。
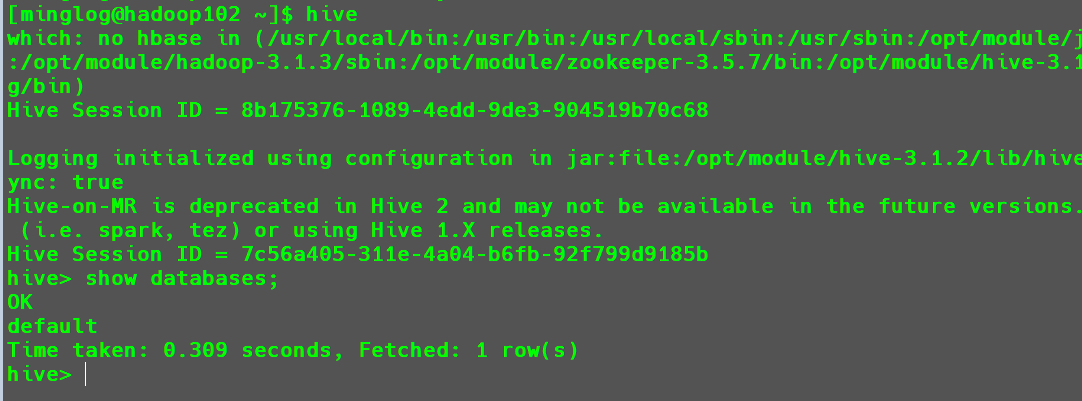
测试结果同样正常,说明使用Mysql作为元数据库,Hive支持客户端并发访问。
元数据之MetaStore Server
元数据服务模式示意图:
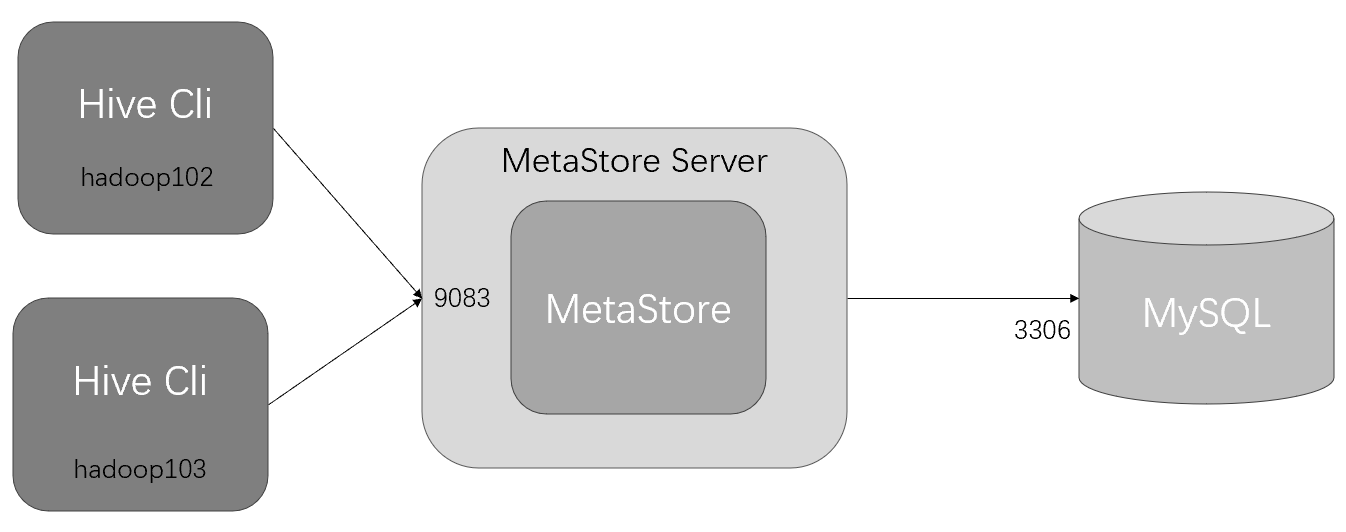
在服务器端启动MetaStore服务,客户端利用Thrift协议通过MetaStore服务访问元数据库。
元数据服务的访问方式更适合在生产环境中部署使用,相比内嵌式,该方式更加的灵活。(跨网络跨语言跨平台)
将Mysql做为元数据库,部署元数据服务。
首先,将hive的元数据库配置为Mysql
1 | vim conf/hive-site.xml |
在hive-site.xml中添加如下配置信息。
1 | <!-- 指定存储元数据要连接的地址 --> |
注意:在配置了此参数后,启动
hive之前必须先启动元数据服务,否则,hive启动后无法连接到元数据服务。如果设置了这个参数,但是没有开启元数据服务,这个时候会导致
Hive服务异常。
在
Hive的日志中也可以看到相关报错。


启动元数据服务。
1 | hive --service metastore |

开启元数据服务后,该SSH窗口就会阻塞,需要重新开启一个SSH窗口启动Hive。

此时Hive服务恢复正常。
这个时候再重新开启一个SSH窗口执行以下命令,查看当前Java进程详细信息。
1 | jps -ml |

可以看到有CliDriver和HiveMetaStore两个Java进程在运行。
连接Hive的两种方式
命令行方式
- 在前面的操作中,我们都是通过
cli的方式访问hive的。 - 我们可以切身的体会到,通过
cli的方式访问hive的不足,如:cli太过笨重,需要hive的jar支持。
HiveServer2模式
JDBC访问Hive示意图
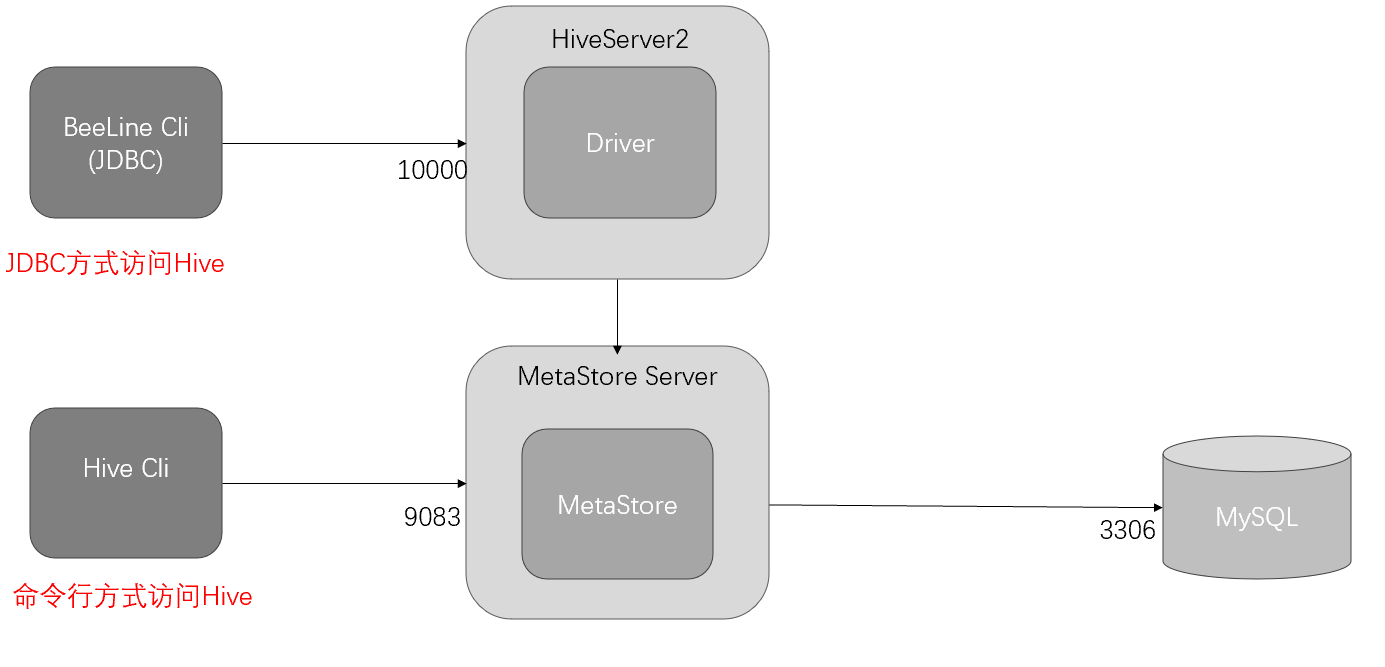
JDBC方式访问Hive
JDBC方式,本质上是将hive包装为服务发布出去,开发者使用JDBC的方式连接到服务,从而操作hive,
减少了对hive环境的依赖。
开启HiveServer2
在hive-site.xml文件中添加如下配置信息。
1 | <!-- 指定hiveserver2连接的host --> |
重启MetaStore服务
1 | hive --service metastore |

启动hiveserver2服务
1 | hive --service hiveserver2 |

启动beeline客户端
1 | beeline -u jdbc:hive2://hadoop102:10000 -n minglog |

Hive简单使用
使用IDEA连接Mysql和Hive
连接Mysql
点击IDEA右侧的数据库侧栏,依次点击+ -> 数据源 -> MySQL
然后下载驱动程序文件
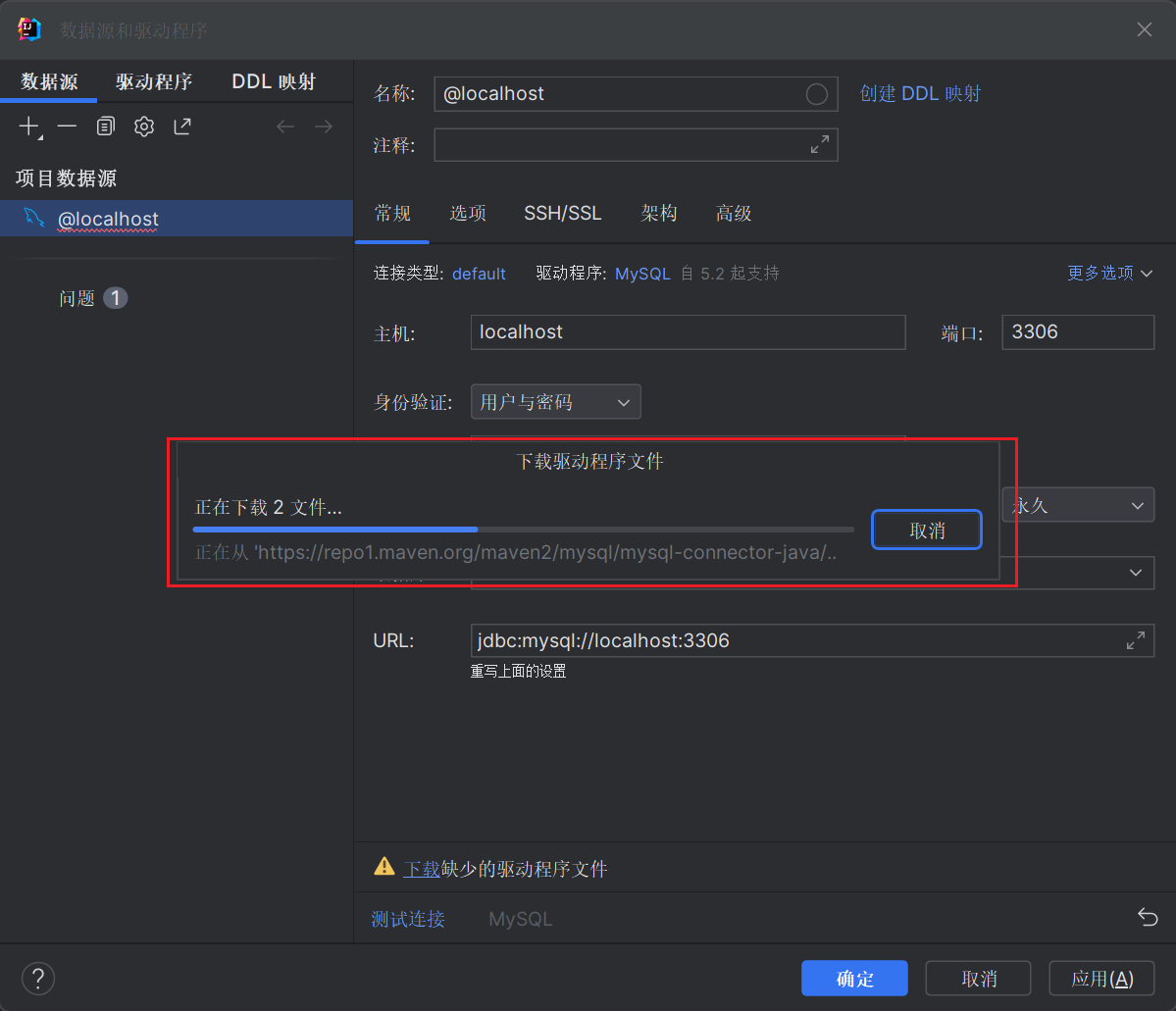
等待下载完成即可。
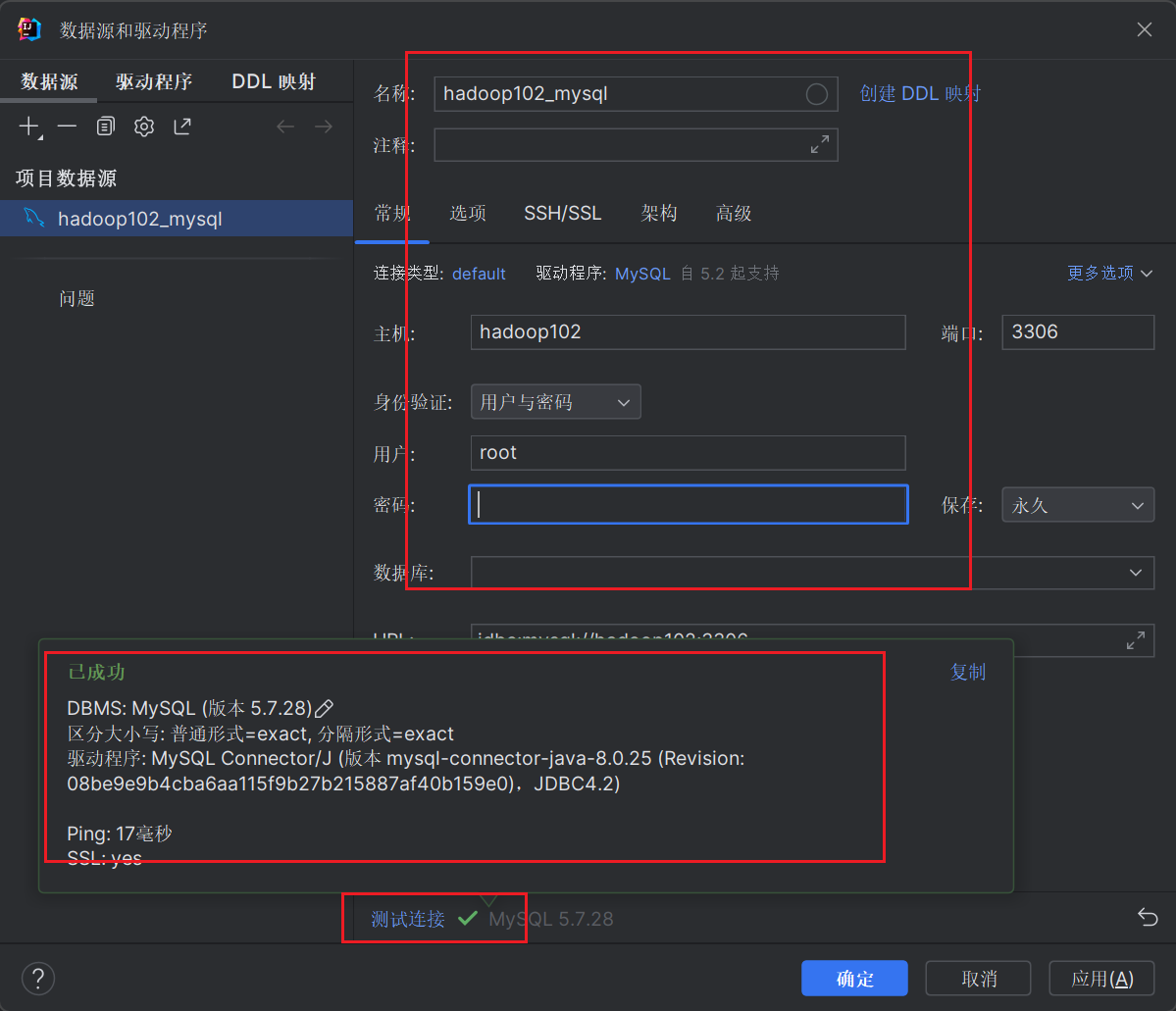
然后设置MySQL数据库的连接信息,如下所示,点击测试连接连接成功后点击确定即可。
此时在侧边栏就会生成对应的数据库连接对象。
连接Hive
首先和前面的操作一样,先在侧边栏中依次点击+ -> 数据源 -> Apache Hive
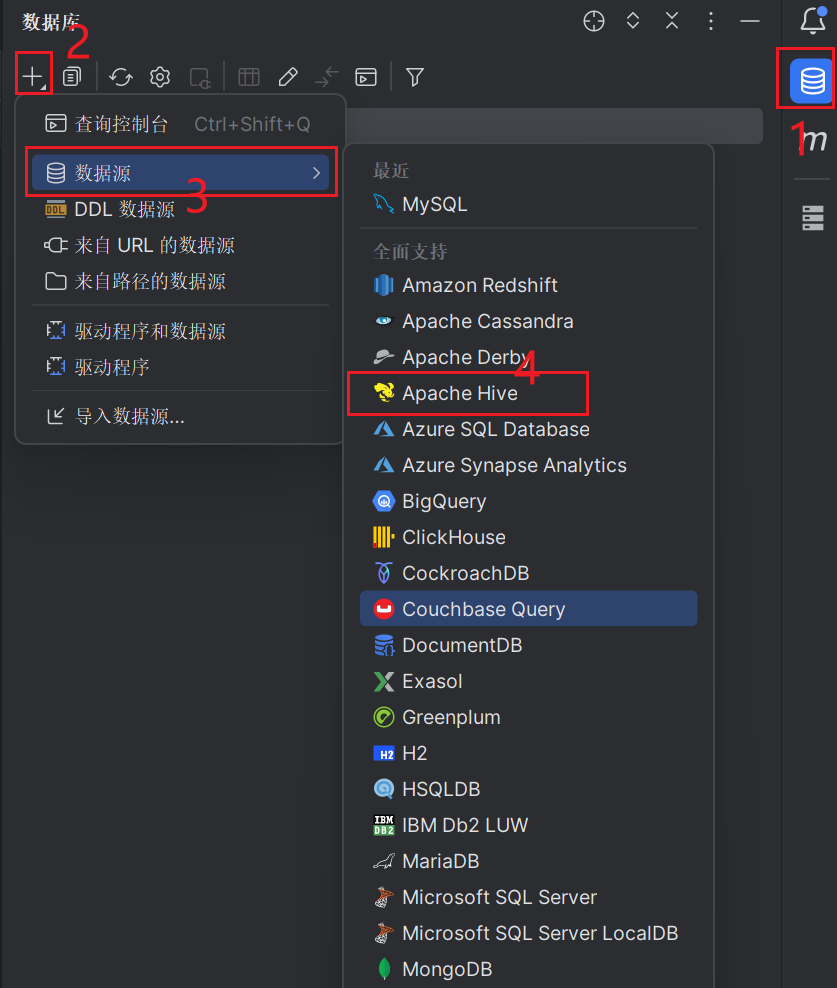
但后点击下载驱动文件。
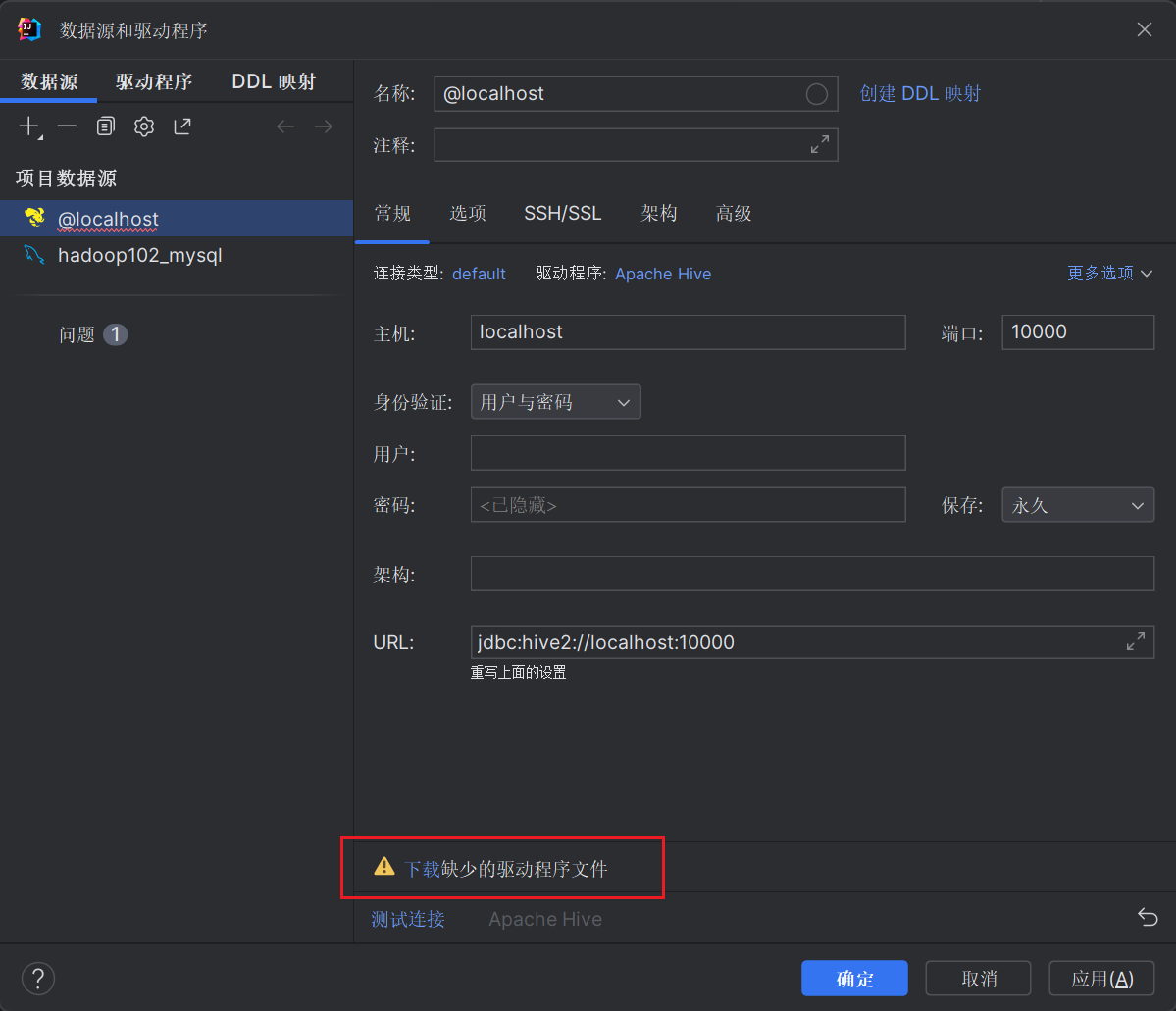
下载完成后参照下图进行Hive信息配置后,点击测试连接,显示连接成功后,点击确定即可。
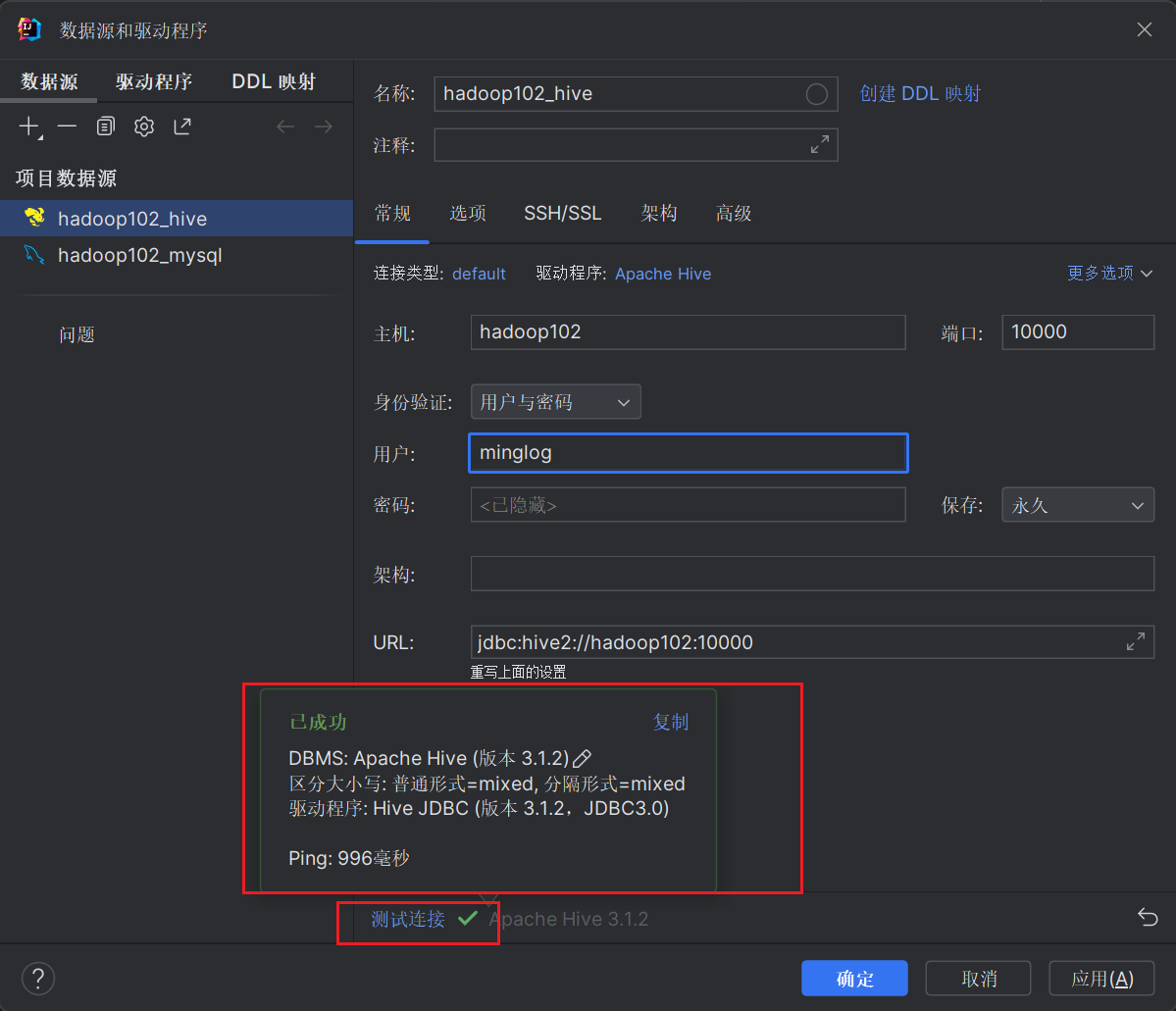
此时在右侧的侧边栏也会多一个Hive连接对象。

并且在IDEA中可以添加控制台直接编写HQL或者SQL代码操作数据库和数据仓库。
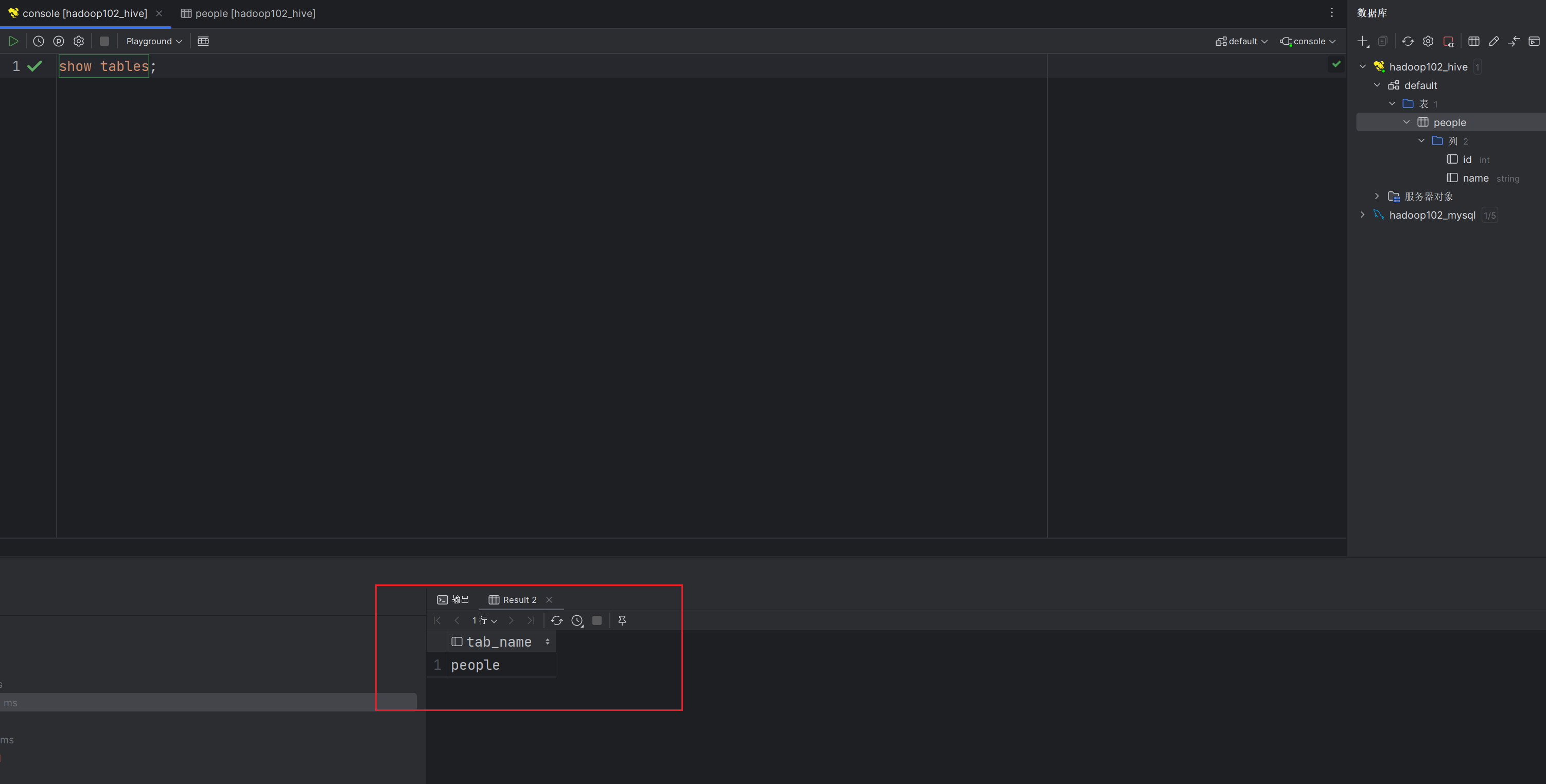
点击相应的表也可以直接查看表中的内容。

Hive启停脚本编写
这部分的内容较为复杂,不要求掌握详细的Shell编写流程,只需会用给出的脚本启动Hive即可。
问题引出,之前每次我们在开启Hive时,都需要先开启MetaStore,再开启HiveSeriver2,并且这两个服务在开启的时候都会把当前窗口变为监听窗口,监听服务。并且窗口还不可以关闭,如果关闭服务也随之停止,这个时候大家都应该想到了在Shell编程中给大家讲到的nohub XXXX &用法,可以保证服务在后台正常运行而不占用当前SSH窗口。
脚本编写如下:
1 |
|
上述脚本写完后保存为hive2.sh名称,赋予执行权限,然后放到用户命令下的bin目录下。
脚本使用方式如下:
启动
Hive1
hive2.sh start


查看
Hive服务状态1
hive2.sh status

注意:
HiveServer2服务开启后需要等一段时间过后在可以正常使用,刚开启完成后直接使用该命令查看状态可能显示成如下内容: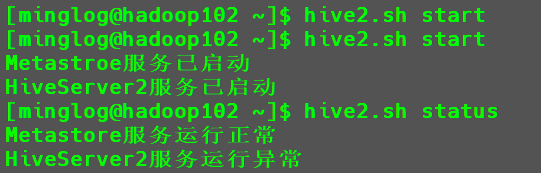
此时只需稍等一段时候过后,再次查看状态就显示正常了。
关闭
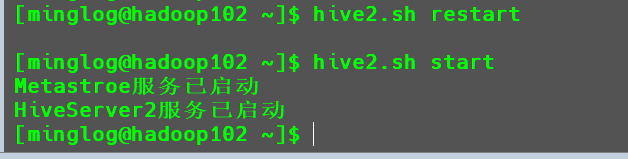
Hive1
hive2.sh stop
重启
Hive1
hive2.sh restart
Hive常用交互命令
使用以下命令可以查看Hive中支持的所有命令。
1 | hive -help |
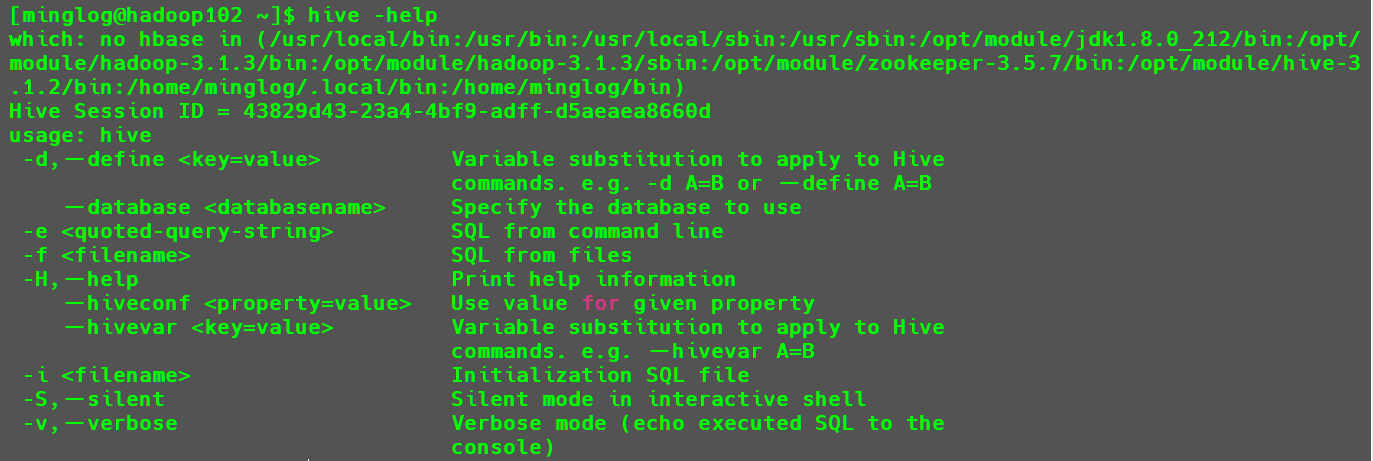
其中用到最多的是两个参数:
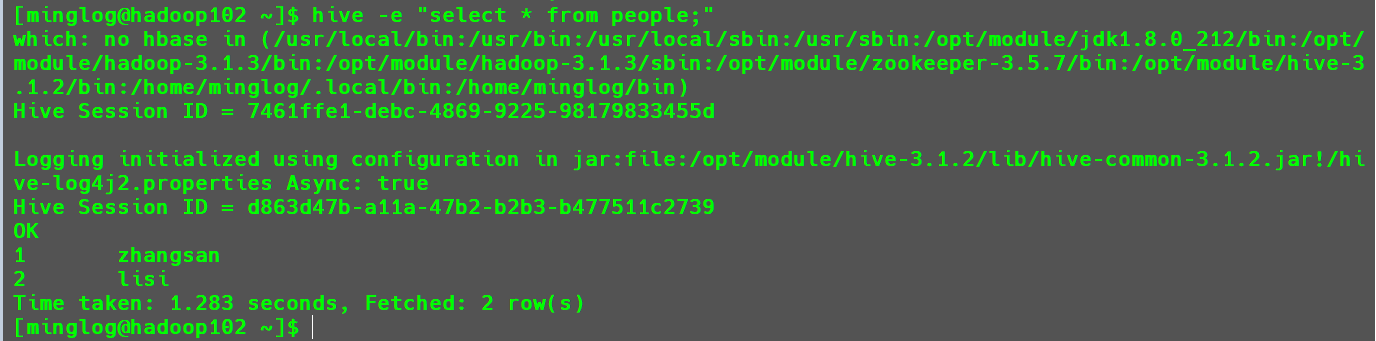
-e:直接指定要在Hive中执行的SQL命令。1
hive -e "select * from people;"
-f:指定要在Hive中运行的SQL脚本。首先新建一个
SQL脚本my_sql.sql。1
2
3
4# 进入家目录
cd ~
# 新建sql脚本
vim my_sql.sql内容如下:
1
select * from people;
执行该脚本:
1
hive -f my_sql.sql
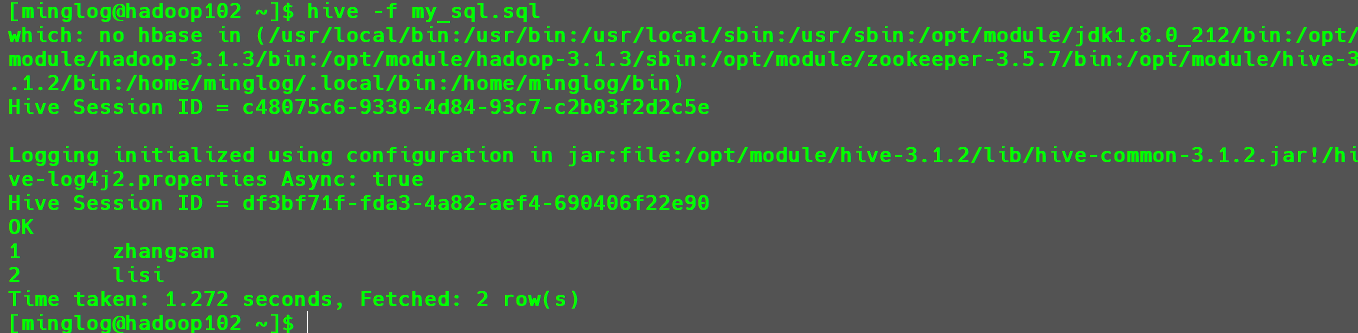
用这两个参数执行
SQL代码有一个好处就是不需要提前进入Hive客户端,而且执行完SQL命令后也不会停留到Hive客户端。
Hive中常见属性配置
修改Hive日志默认存储路径
默认的情况下Hive的日志存储在以下目录/tmp/minglog/hive.log(当前用户的临时目录下)。而/tmp目录在Linux中表示的是临时目录,临时目录意味着系统会定期清楚该目录中的文件,这样可能就会导致日志丢失,所以修改Hive日志的默认存储路径是很有必要的。

修改步骤如下。
修改conf目录下hive-log4j2.properties.template文件名称为hive-log4j2.properties。
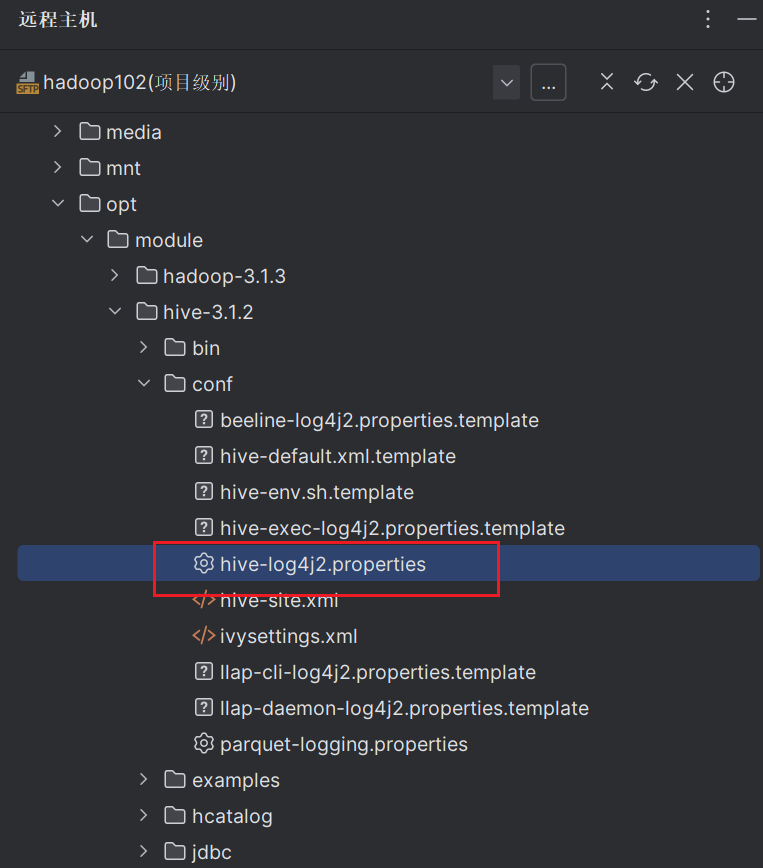
在hive-log4j.properties文件中修改log存放位置。
1 | property.hive.log.dir=/opt/module/hive-3.1.2/logs |
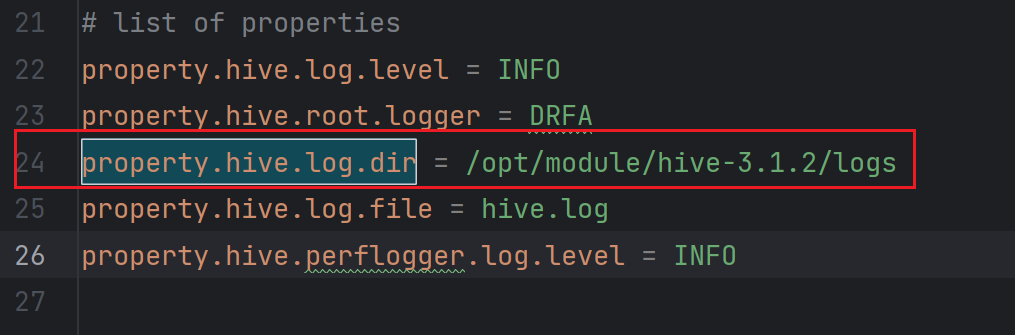
然后重启Hive。重启后在/opt/module/hive-3.1.2/logs目录下就会生成hive.log日志文件。
Hive启动JVM堆内存配置
新版Hive启动时,默认申请的JVM堆内存大小为256M,内存太小,导致若后期开启本地模式,执行相对复杂的SQL经常会报错:java.lang.OutOfMemoryError: Java heap space。
解决办法为,扩大JVM堆内存大小为1024M,具体操作如下所示。
修改/opt/module/hive/conf/下的hive-env.sh.template文件为hive-env.sh。
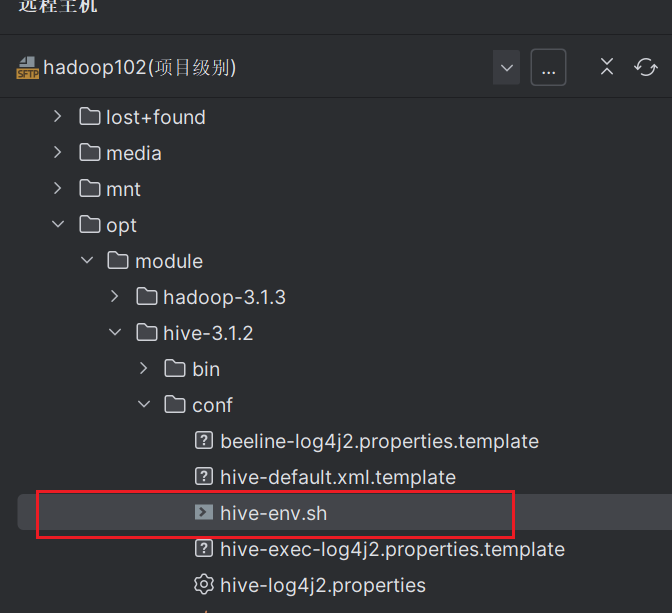
修改以下内容:
1 | export HADOOP_HEAPSIZE=1024 |
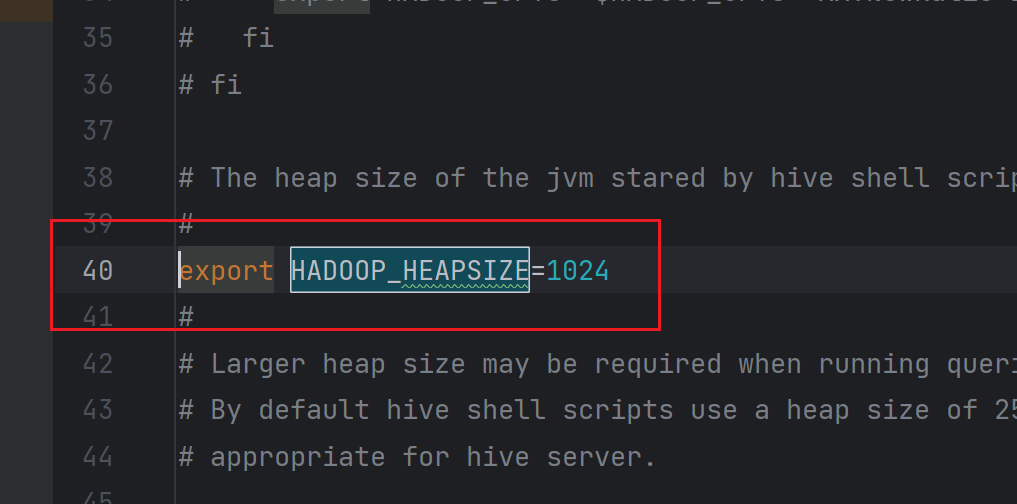
重启Hive服务即可生效。
hive窗口打印默认库和表头
默认的情况下,使用命令在Hive查看表中的数据时,是没有显示每一列的字段名称和当前表格所处数据库的,这对于不熟悉数据的开发者十分不友好,可以采用修改hive-site.xml中hive.cli.print.current.db和hive.cli.print.header两个参数的值都为true,分别打印出当前库头和表头。
1 | <!-- 打印字段名称--> |
配置完后重启Hive。
- 配置前。
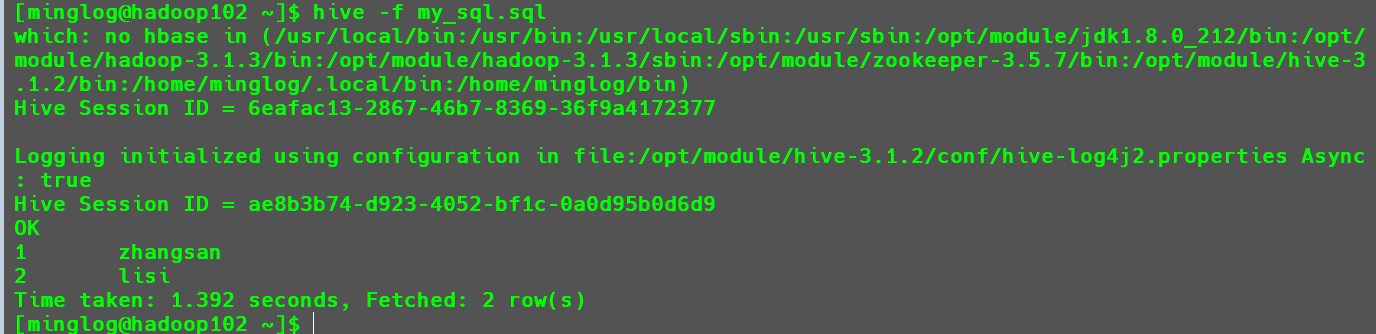
- 配置后。
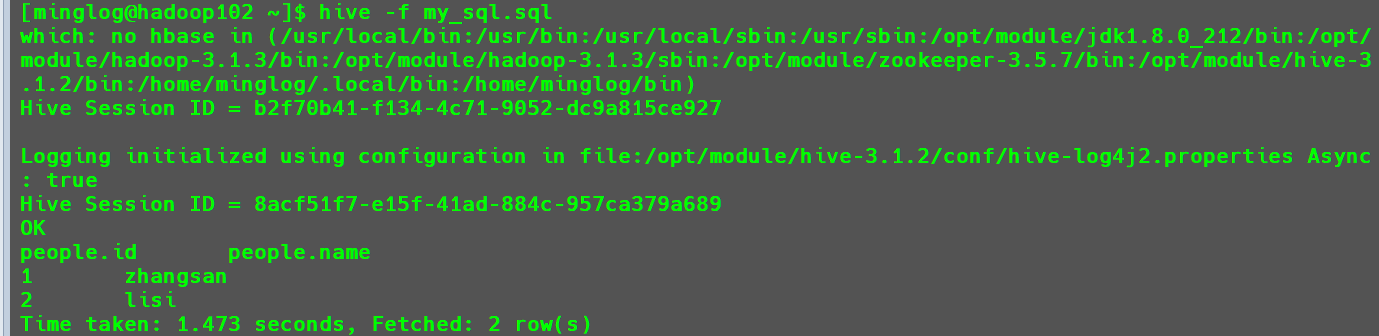
直接输入hive进入Hive客户端,也可以看到当前选择的数据库名称。
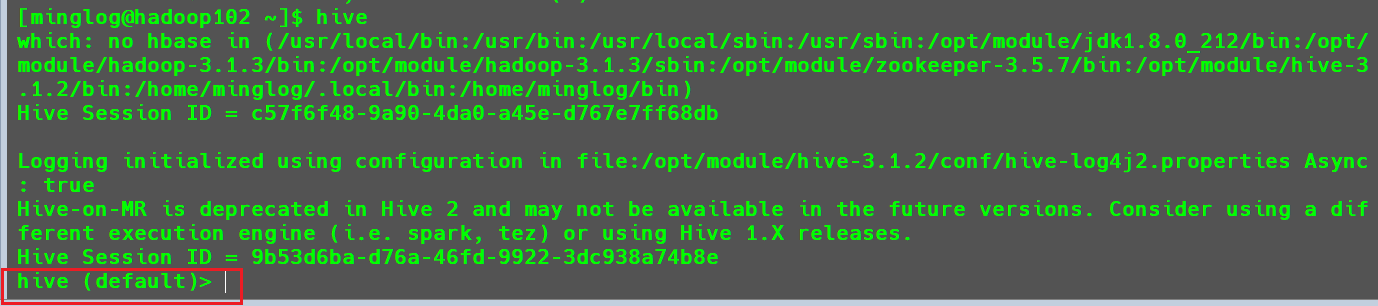
配置参数的其他两种方式
命令行配置方式
启动hive时,可以在命令行添加--hiveconf param=value来设定参数。
例如,我们现在设置不让他显示库头。
1 | hive --hiveconf hive.cli.print.current.db=false |
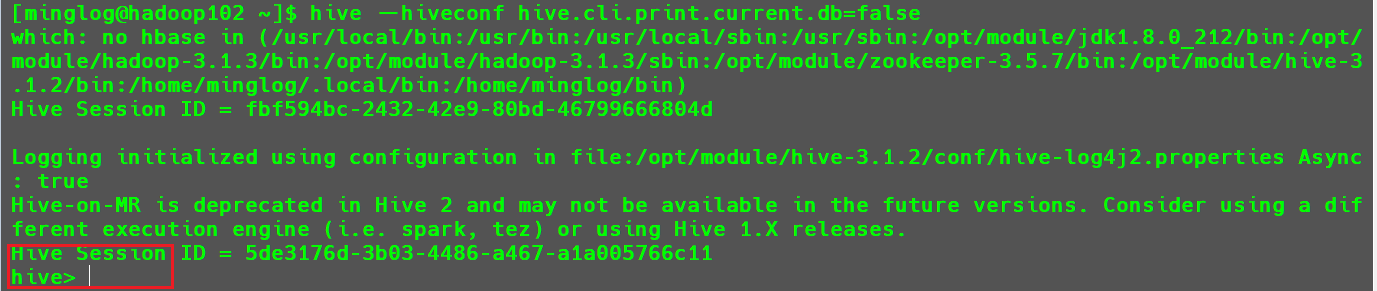
此时进入的hive客户端中就不存在库头了。
该方式设置的参数,只在当前
Hive客户端会话中生效。当我们有些命令只想在某个配置参数下运行时,可以使用该方式设置配置参数。
在进入hive命令行交互窗口后,可使用set命令设置参数
首先,直接输入hive进入Hive客户端。
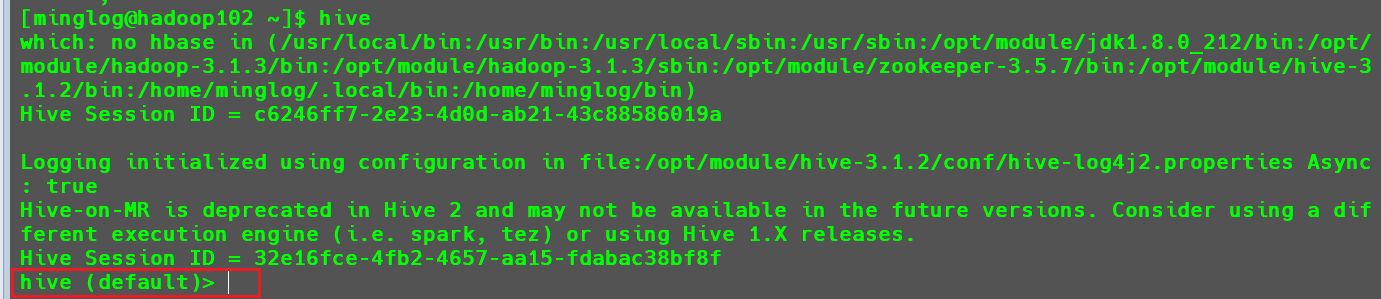
接下来使用以下命令设置参数。
1 | set hive.cli.print.current.db=false; |
可以看到执行完该命令后,库头就消失了。
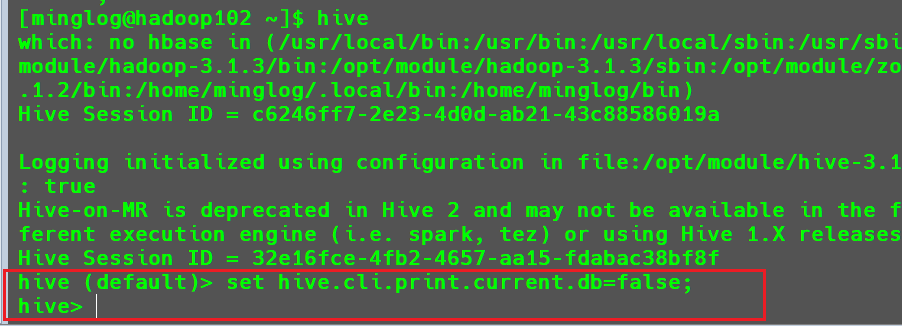
该方式设置的参数,也是只在当前
Hive客户端会话中生效。当我们有些命令只想在某个配置参数下运行时,可以使用该方式设置配置参数。
总结:现在我们一共讲了3种设置参数的方法。
- 修改
hive-site.xml文件内容。 - 命令行配置方式。
- 在进入hive命令行交互窗口后,可使用set命令设置参数。
这三种方式的优先级如下所示:3 > 2 > 1。