项目介绍 本项目旨在构建一个“语音驱动的数字人”,通过语音识别、自然语言理解与语音合成,实现与用户的自然对话交互。用户只需对着麦克风说话,系统即可自动识别语音内容,通过大语言模型生成回答,并将结果实时语音播放,提供类人对话体验。
核心流程如下:
用户说话
Whisper 识别语音转文本(ASR)
使用 Ollama 本地大模型理解/回答问题(LLM)
使用 EdgeTTS 语音合成回答内容(TTS)
播放生成的语音回应
该系统适用于智能助手、教育机器人、客户服务等场景,支持本地部署,保障数据安全与响应速度。
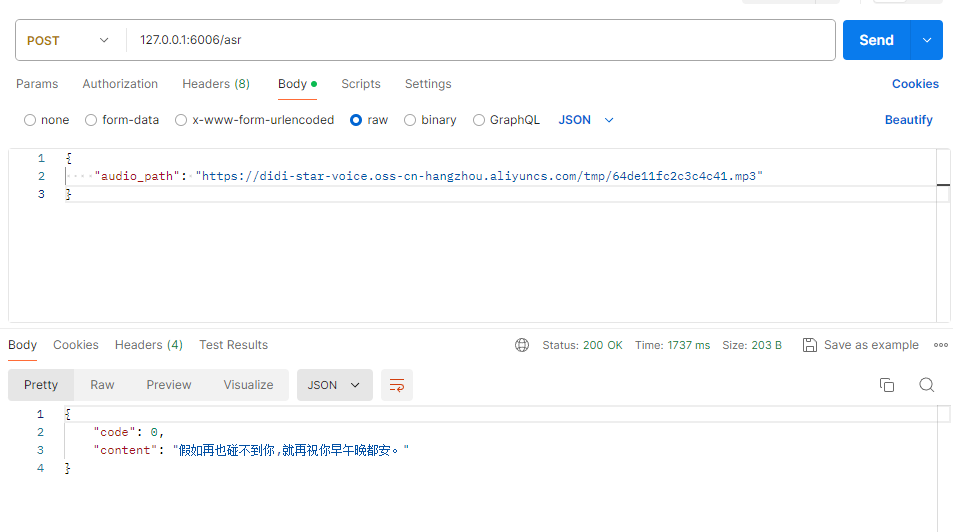
相关技术介绍 ASR—— 把“你说的话”变成文字 ASR 就是语音识别。也就是把你说的话变成文字 ,交给 AI 处理。
现在我们常用的是 OpenAI 出的 Whisper :
它支持中文、英文、混合语言
噪音大、口音重也能识别得不错
可以本地运行,不用联网,非常适合做成一个“本地数字人”
ASR 就是给 AI 加上“耳朵”,让它能听懂人说话 ,转成文字再处理。
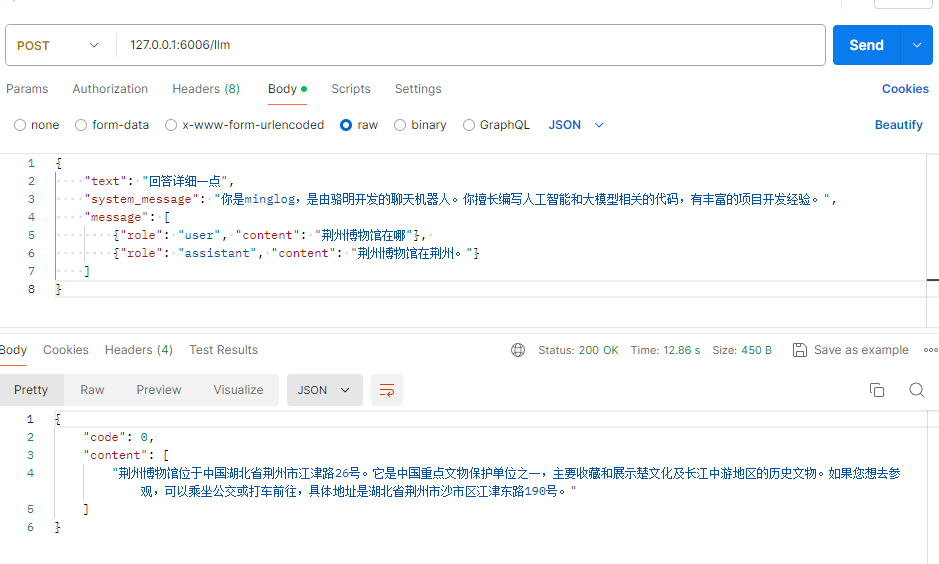
Prompt —— 让大模型“懂你说的话”并“会说人话” Prompt 是指用于引导大语言模型(如 LLaMA、ChatGPT、Gemini 等)输出期望内容的文本提示。在本项目中,Prompt 决定了模型扮演的角色、语气、语言风格和上下文理解能力。
Prompt 就像是我们给大脑下的指令 ,告诉它:“你现在是谁?你应该怎么说话?你要干什么?”
在语音数字人里,我们用 Prompt告诉大模型:
你是一个什么样的人?(比如“你是一个温柔有耐心的儿童陪伴机器人”)
你要用什么语气说话?(比如“请用亲切、简单的语言回答”)
用户刚才说了什么?(我们把用户的话拼接进去)
Prompt就是提示词 ,用来“教会”模型说什么、怎么说,让 AI更像一个“会聊天的人”。
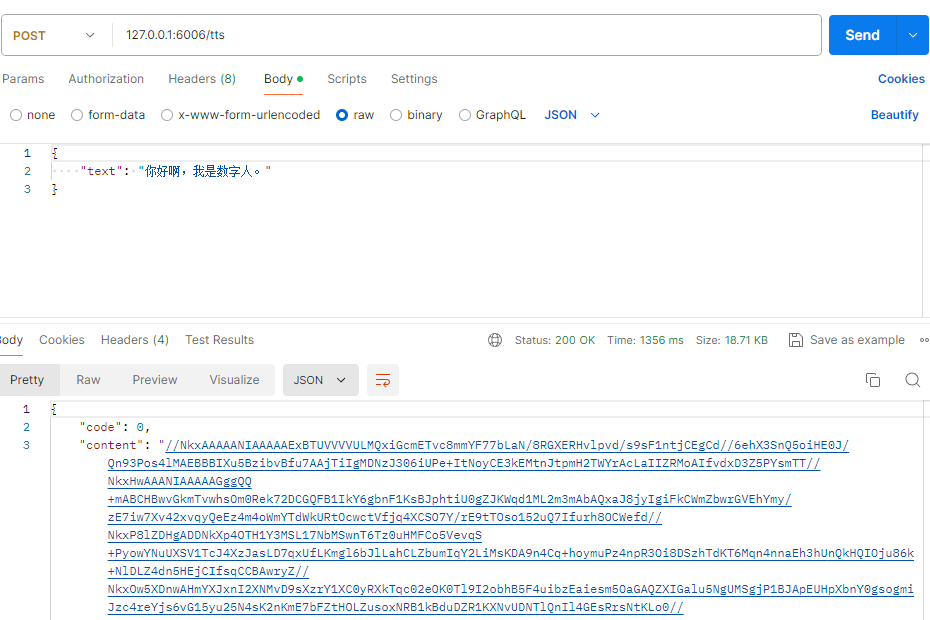
TTS—— 把文字变成“会说话的声音” TTS 就是语音合成。简单说,就是把写出来的文字变成能听到的声音 。
微软的 EdgeTTS 是一种常用的方法:
它能合成中文、英文等多种语言
声音很多种:比如“男声”、“女声”
还能控制语速、语调等等
TTS 就是给 AI加上“嘴巴”,让它把回答读出来 ,让我们听得见。
总结
技术
作用
通俗说法
ASR
听懂你说话
AI 的“耳朵”
Prompt
想明白怎么说
AI 的“大脑提示”
TTS
把话说出来
AI 的“嘴巴”
项目开发 上传模型权重 由于上传权重的过程比较耗时,所以我们在做其他工作之前,先把模型权重上传到服务器。
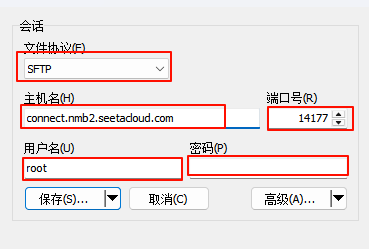
可以使用winscp工具上传模型权重,工具下载地址:https://winscp.net/eng/index.php
下载安装完成后,点击新建标签页使用sftp协议连接服务器。
输入相关信息进行连接
相关信息可以在AutoDL实例页面获取。
点击复制后,可以获取登录的命令和密码。
格式如下所示:
1 2 ssh -p 14177 root@connect.nmb2.seetacloud.com xxxxxxxxxxx
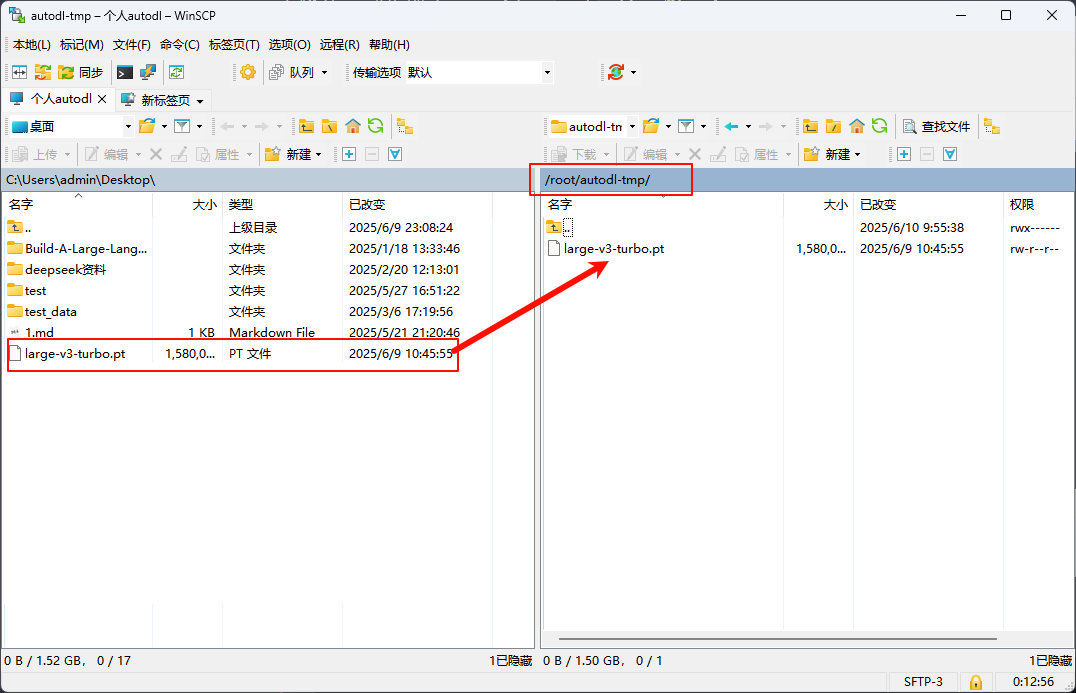
连接完成后,可以通过拖拽的方式将准备好的权重文件上传到服务器的/root/autodl-tmp目录。
模型权重下载地址: https://pan.baidu.com/s/1d2TYqx_uwveOin72Z9Js3A?pwd=ming
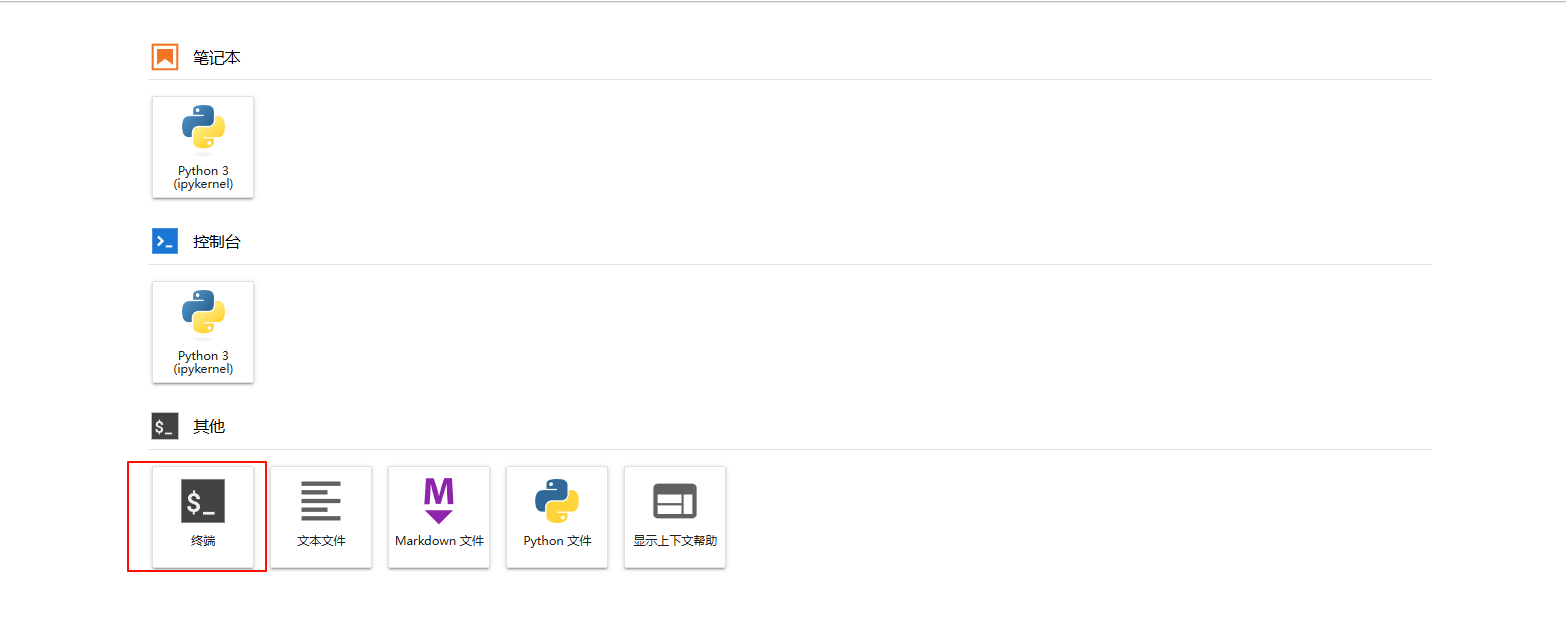
基础环境部署 在AutoDL官网实例页面,点击自己刚刚创建的实例JupyterLab。
然后新建终端
更新相关Ubuntu
1 2 apt update && apt upgrade apt-get update && apt-get upgrade
下载ffmpeg和tmux工具
查看ffmpeg工具版本
安装uv工具
查看uv工具版本
至此,基础环境部署完成。
OLLAMA部署 进入到/root/autodl-tmp目录,并开启学术加速
1 cd /root/autodl-tmp && source /etc/network_turbo
然后执行以下命令,下载ollama安装文件
1 curl -L https:// ollama.com/download/ ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz
解压并部署ollama
1 sudo tar -C /usr -xzf ollama-linux-amd64.tgz
接下来编辑/root/.bashrc文件,设置ollama模型的存储目录和端口。
1 2 export OLLAMA_HOST="0.0.0.0:6008" export OLLAMA_MODELS=/root/autodl-tmp/ollama/models
编辑时需要使用vim命令,这个工具的用法可以去自行百度。
接下来,重新加载配置文件。(重启终端也可以)
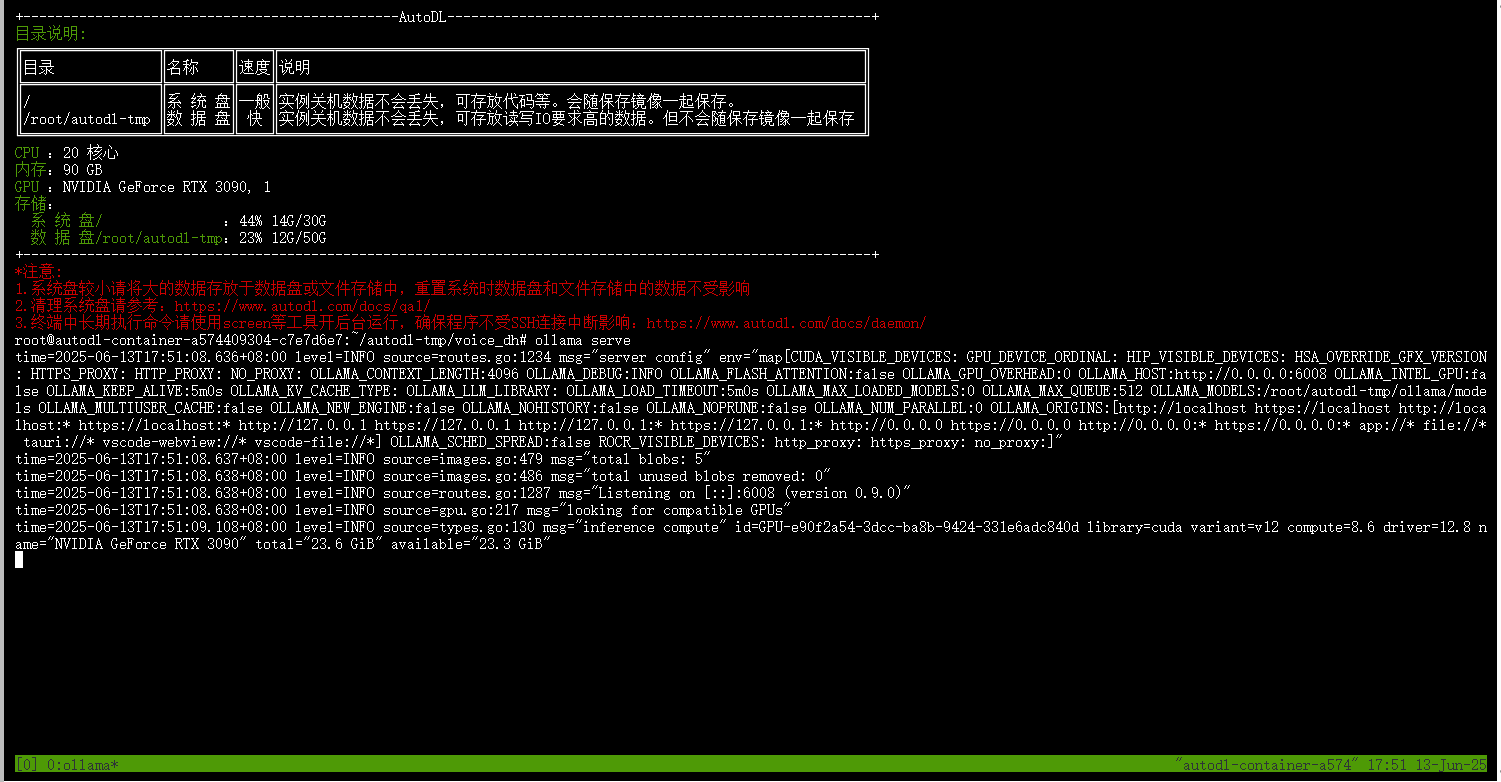
开启ollama服务,查看服务是否正常
可以看到ollama服务成功开启在6008端口。
这个时候需要注意了,这个黑色窗口不能关闭,如果关闭了会导致ollama服务也会一起结束。但是,我们又不能一直把网站打开,我们希望服务部署好后,服务可以离线托管,这显然是不符合我们的项目需求的。要解决这个问题,就需要使用到我们前面下载的tmux工具,这个工具可以做到离线托管终端代码。
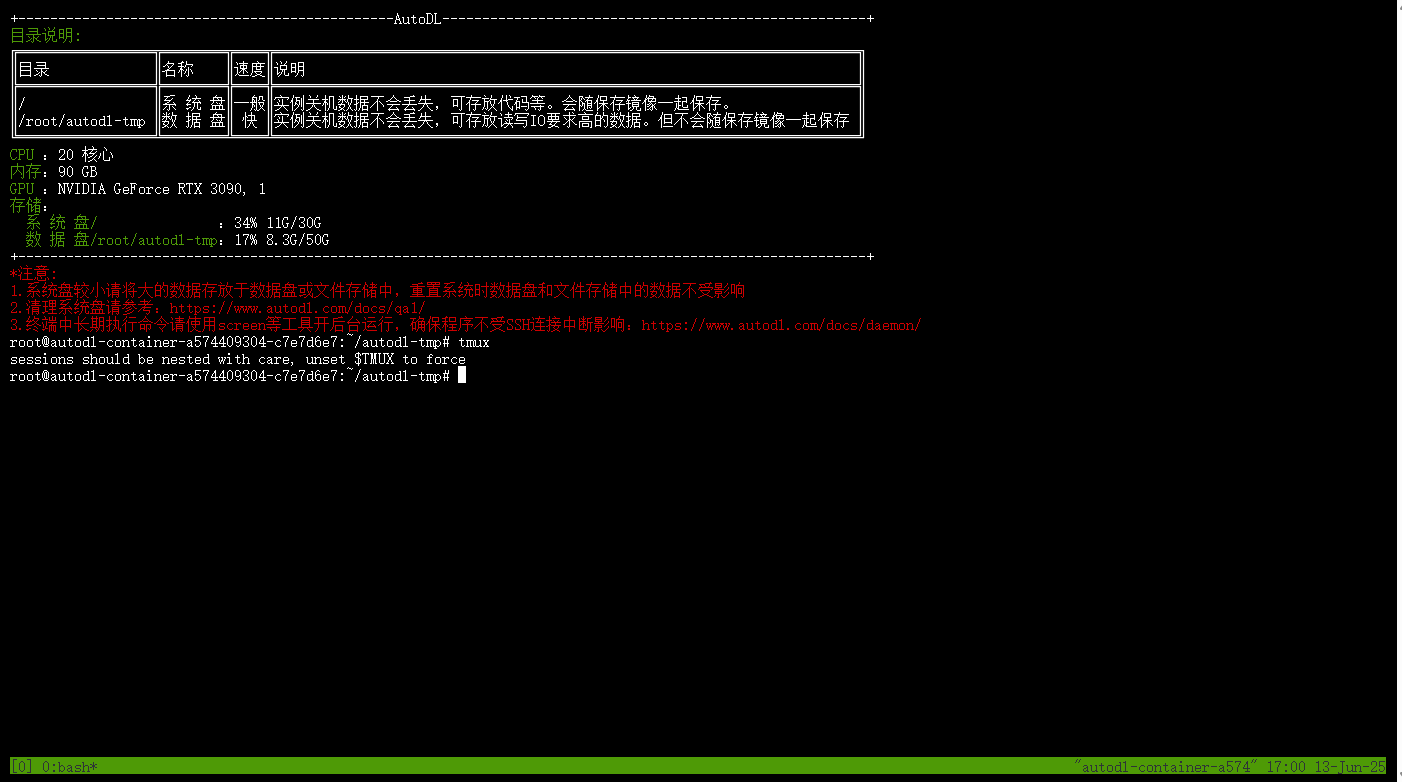
直接在终端输入tmux,回车。该工具就会自动给我们创建一个可以用于离线托管的终端。
在该终端下,开启ollama服务。
接下来就是关键的步骤,如何退出这个终端让终端在后台执行呢?
tmux工具提供了快捷命令,ctrl B+ d即可完成终端托管。
此时,终端会自动退回到我们之前使用的终端。
我们可以通过以下命令,查看所有的后台终端
进入到某个后台终端
这个命令中的0可以替换为其他终端的编号。
接下来,让我们测试一下ollama服务是否还可以正常使用。使用ollama下载qwen2.5:7b模型,并进行对话测试。
如果在这一步发生报错:Error: something went wrong, please see the ollama server logs for details。可以重启一下服务器,再次尝试下载。
等待模型安装完成后,会自动开启一个终端对话窗口,接下来就可以输入文字和大模型进行对话了。
至此,OLLAMA完成部署。
项目创建 进入到autodl-tmp目录
使用uv工具创建项目
1 uv init voice_dh -p 3.11
初始化一个名为voice_dh的项目,并指定Python版本为3.11。
进入项目目录,并开启学术资源加速,防止后续下载速度过慢
1 cd voice_dh && source /etc/network_turbo
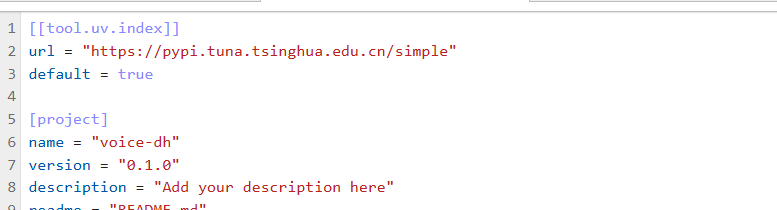
接下来手动修改voice_dh下的pyproject.toml文件,添加国内镜像。
1 2 3 [[tool.uv.index]] url = "https://pypi.tuna.tsinghua.edu.cn/simple" default = true
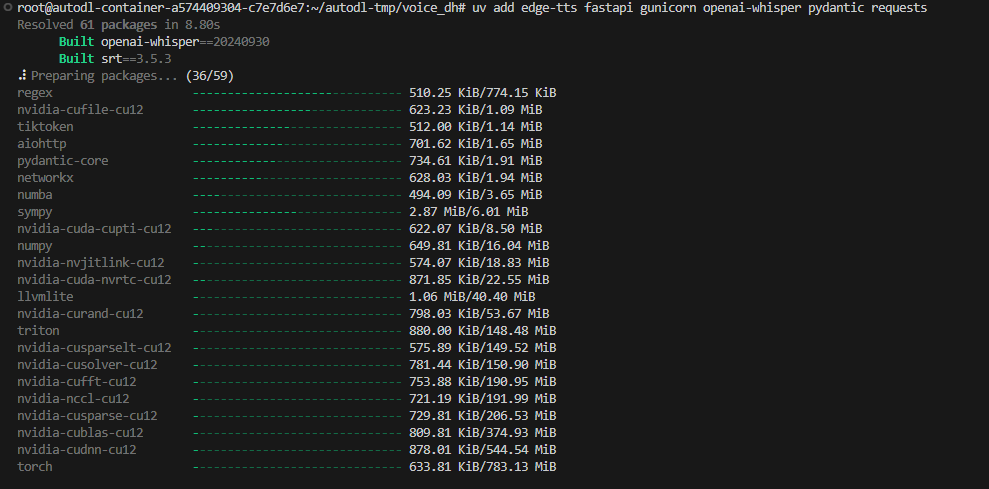
接下来,安装依赖。
1 uv add edge-tts fastapi gunicorn openai-whisper pydantic requests uvicorn
此处安装的依赖数量有点多,估计会耗时10分钟左右。
在依赖安装过程中,可以先把项目的结果创建好
然后将前面上传的模型权重移动到model目录下。
1 mv ../large-v3-turbo.pt model
等待依赖彻底安装完成后,再继续下面的步骤。
创建工具脚本 首先,在项目目录下的utils目录下创建utils.py文件,文件内容如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import loggingfrom datetime import datetimefrom uuid import uuid4import base64logging.basicConfig(level=logging.INFO, format ='%(asctime)s - %(levelname)s - %(message)s' ) logger = logging.getLogger(__name__) def gen_random_job_id (random_str_len=10 ): return datetime.now().strftime("%Y%m%d_%H%M%S" ) + "_" + uuid4().hex [:random_str_len] def audio_to_base64 (audio_path ): with open (audio_path, "rb" ) as audio_file: return base64.b64encode(audio_file.read()).decode("utf-8" ) def base64_to_audio_file (base64_string, output_path ): audio_bytes = base64.b64decode(base64_string) with open (output_path, "wb" ) as f: f.write(audio_bytes) return output_path
该代码的作用是存放一些公共的工具,这里主要是四个工具:
logger:用于记录日志。gen_random_job_id:用于生成随机字符串,便于后续存储临时文件。audio_to_base64:用于将音频文件转化为Base64编码。base64_to_audio_file:用于将Base64编码还原为文件。
需要注意的是,在本项目中涉及到大量的音频交互,要想使用音频在客户端和服务器之间传递,通常有两种办法。
使用音频公网地址。【例如:上传到OSS,构建个人云存储服务等等】
使用base64进行编解码。服务端将音频文件编码为Base64格式,发送给客户端。客户端拿到Base64编码后,再进行解码。
这里我们采用的是第二种方式。
ASR功能实现 在项目下的utils目录中创建asr.py文件,然后在文件中输入以下代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 import syssys.path.append(".." ) from abc import abstractmethodimport requestsimport timeimport osimport whisperfrom .utils import gen_random_job_id, base64_to_audio_fileclass BaseASR : def __init__ (self ): ... @abstractmethod def audio2txt (self, audio: str ) -> str : raise NotImplementedError("Please implemented audio2txt function." ) def __call__ (self, audio: str ) -> str : text = self.audio2txt(audio).strip() return text class WhisperASR (BaseASR ): def __init__ (self ): super (WhisperASR, self).__init__() self.whisper_model = whisper.load_model("turbo" , download_root="model" ) self.tmp_save_dir = "./tmp" if not os.path.exists(self.tmp_save_dir): os.makedirs(self.tmp_save_dir, exist_ok=True ) def audio2txt (self, audio ): tmp_imgpath = os.path.join(self.tmp_save_dir, f"{gen_random_job_id()} .mp3" ) if audio.startswith(('http://' , 'https://' )): response = requests.get(audio) with open (tmp_imgpath, 'wb' ) as f: f.write(response.content) elif len (audio) > 100 : tmp_imgpath = base64_to_audio_file(audio, tmp_imgpath) result = self.whisper_model.transcribe(tmp_imgpath)["text" ] os.remove(tmp_imgpath) return result if __name__ == "__main__" : asr_model = WhisperASR() audio = "test.mp3" res = asr_model(audio) print (res)
在该代码中定义了两个类:
BaseASR:该类为ASR功能的基类,其他所有的ASR工具都可以继承该类,用于规范ASR工具的统一调用。继承自该类的工具,只需要重写audio2txt的具体逻辑就可以直接统一功能调用方式。WhisperASR:该类是继承自BaseASR的一个工具类,用于实现调用WhisperASR功能的逻辑。
功能测试:
在main.py文件中输入以下内容。
1 2 3 4 5 6 7 from utils.asr import WhisperASR asr_model = WhisperASR() audio = "https://ming-log.oss-cn-hangzhou.aliyuncs.com/tmp/test.mp3" res = asr_model(audio) print (res)
接下来执行以下命令,运行main.py脚本:
1 /root/autodl-tmp/voice_dh/.venv/bin/python main.py
测试成功。
TTS功能实现 在项目下的utils目录中创建tts.py文件,然后在文件中输入以下代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 import edge_ttsfrom abc import abstractmethodfrom .utils import loggerclass BaseTTS : def __init__ (self ): self.name = "base_tts" @abstractmethod def get_audio (self, text, save_path ): """ text: 待转化文本 save_path: 音频保存路径,这里应该是一个临时文件,上传到OSS后会删除 return: 保存的音频文件路径 """ raise NotImplementedError('Please implemented get_audio function.' ) def __call__ (self, text, save_path ): return self.get_audio(text, save_path) class EdgeTTS (BaseTTS ): def __init__ (self, voice_id="zh-CN-XiaoxiaoNeural" , speed=0.0 , vol=0.0 , pitch=0.0 ): super (EdgeTTS, self).__init__() self.name = "edge_tts" self.voice_id = voice_id self.rate = speed self.volume = vol self.pitch = pitch async def atts (self, text, save_path, ratestr, volstr, pitchstr ): communicate = edge_tts.Communicate(text, self.voice_id, rate=ratestr, volume=volstr, pitch=pitchstr) await communicate.save(save_path) async def get_audio (self, text, save_path ): if self.rate>=0 : ratestr=f"+{int (self.rate)} %" elif self.rate<0 : ratestr=f"{int (self.rate)} %" if self.volume >= 0 : volstr=f"+{int (self.volume)} %" elif self.volume<0 : volstr=f"{int (self.volume)} %" if self.pitch >= 0 : pitchstr=f"+{int (self.pitch)} Hz" elif self.pitch<0 : pitchstr=f"{int (self.pitch)} Hz" for _ in range (3 ): logger.info(f"EdgeTTS -- voice_id:{self.voice_id} | save_path:{save_path} " ) try : await self.atts(text=text, save_path=save_path, ratestr=ratestr, volstr=volstr, pitchstr=pitchstr) return save_path except Exception as e: logger.error(f"EdgeTTS: {e} " ) return None async def __call__ (self, text, save_path ): return await self.get_audio(text, save_path) if __name__ == '__main__' : text = """你好啊,很高兴认识你。""" audio_path = f"tmp/test.mp3" tts_fun = EdgeTTS() audio_file = tts_fun(text, audio_path) print (audio_file)
在该代码中定义了两个类:
BaseTTS:该类为TTS功能的基类,其他所有的TTS工具都可以继承该类,用于规范TTS工具的统一调用。继承自该类的工具,只需要重写get_audio的具体逻辑就可以直接统一功能调用方式。EdgeTTS:该类是继承自BaseTTS的一个工具类,用于实现调用EdgeTTS功能的逻辑。
功能测试:
将之前的代码注释,添加新代码,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from utils.tts import EdgeTTSimport asynciotext = """你好啊,很高兴认识你。""" audio_path = f"test.mp3" tts_model = EdgeTTS() audio_file = asyncio.run(tts_model(text, audio_path)) print (audio_file)
接下来执行以下命令,运行main.py脚本:
1 /root/autodl-tmp/voice_dh/.venv/bin/python main.py
测试成功,在项目目录下会生成一个test.mp3文件。将文件下载到本地机器就可以听到语音内容。
LLM功能实现 在项目下的utils目录中创建llm.py文件,然后在文件中输入以下代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 import requestsimport jsonfrom abc import abstractmethodimport tracebackimport timeDEFAULT_SYSTEM_MESSAGE = "你是一个人工智能助手!" class BaseChat : def __init__ (self, system_message=DEFAULT_SYSTEM_MESSAGE, url="" , model_name="" ): self.url = url self.model_name = model_name self.system_message = { "role" : "system" , "content" : f"""{system_message} """ } self.message = [self.system_message] self.headers = { "Content-Type" : "application/json" } @abstractmethod def _ouput_response (self, response, stream=False ): raise NotImplementedError('Please implemented __output_response function.' ) def chat (self, prompt, message=[], stream=False , system_message=None , max_message_num=-1 , **options ): """ Chat Model. Automatically record contexts. prompt: Type Str, User input prompt words. messages: Type List, Dialogue History. role in [system, user, assistant] stream: Type Boolean, Is it streaming output. if `True` streaming output, otherwise not streaming output. system_message: Type Str, System Prompt. Default self.system_message. max_message_num: For controlling the number of contexts(Exclude System Prompt). Default -1(Means: No control over context length) **options: option items. Example temperature, max_tokens, top_p, etc. """ if system_message: self.system_message["content" ] = system_message self.message = [self.system_message] + message self.message.append({"role" : "user" , "content" : prompt}) if 'max_tokens' in options: options['num_ctx' ] = options['max_tokens' ] if max_message_num != -1 and len (self.message) >= (max_message_num*2 -1 ): self.message = self.message[0 :1 ] + self.message[-max_message_num*2 -1 :] data = { "model" : self.model_name, "messages" : self.message, "options" : options, "stream" : stream, "parameters" : options } data.update(options) responses = requests.post(self.url, headers=self.headers, json=data, stream=stream) try : return_text = self._ouput_response(responses, stream) except : print ("Response:" , responses.text) traceback.print_exc() return_text = "出错了,请向开发人员反馈!" return return_text def generate (self, prompt, stream=False , system_message=None , **options ): ''' Generate Model. No record contexts. prompt: Type Str, User input prompt words. stream: Type Boolean, Is it streaming output. if `True` streaming output, otherwise not streaming output. **options: option items. Example temperature, max_tokens, top_p, etc. ''' return_text = self.chat(prompt, message=[], stream=stream, system_message=system_message, **options) return return_text class OllamaChat (BaseChat ): ''' 开发文档地址:https://github.com/ollama/ollama/blob/main/docs/api.md ''' def __init__ (self, system_message=DEFAULT_SYSTEM_MESSAGE, url="http://localhost:6008/api/chat" , model_name="qwen2.5:7b" ): super (OllamaChat, self).__init__(system_message, url, model_name) def _ouput_response (self, response, stream=False ): if stream: return_text = '' for chunk in response.iter_content(chunk_size=2048 ): if chunk: text = json.loads(chunk.decode('utf-8' ))['message' ]['content' ] return_text += text yield text else : return_text = '' .join([json.loads(response)['message' ]['content' ] for response in response.text.split('\n' ) if len (response) != 0 ]) yield return_text if __name__ == "__main__" : Chat = OllamaChat() start_time = time.time() res = Chat.chat("你好" , stream=False ) for i in res: print (i) stop_time = time.time() print ("耗时:" , stop_time-start_time)
在该代码中定义了两个类:
BaseChat:该类为LLM功能的基类,其他所有的LLM工具都可以继承该类,用于规范LLM工具的统一调用。继承自该类的工具,只需要重写_ouput_response的具体逻辑就可以直接统一功能调用方式。OllamaChat:该类是继承自BaseChat的一个工具类,用于实现利用Ollama部署大模型的调用。
执行以下命令测试工具是否正常。
1 /root/ autodl-tmp/voice_dh/ .venv/bin/ python utils/llm.py
测试成功。
API接口编写 前面我们已经将所有功能全部实现,并测试成功了,但是这个代码和环境部署都是在autodl的服务器中进行的,我们本地编写代码无法直接去调用这些功能,要想实现在本地调用相关工具,那么就需要在服务器中编写相关接口,为外部调用工具时提供服务。
在项目根目录下创建api.py文件,并填入以下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 import os, base64if not os.path.exists("tmp" ): os.makedirs("tmp" ) from uuid import uuid4from pydantic import BaseModelimport fastapifrom utils.asr import WhisperASRfrom utils.llm import OllamaChatfrom utils.tts import EdgeTTSfrom utils.utils import gen_random_job_id, audio_to_base64app = fastapi.FastAPI() asr_model = WhisperASR() llm_model = OllamaChat() tts_model = EdgeTTS() class AudioItem (BaseModel ): audio_path: str class LLMItem (BaseModel ): text: str message: list [dict [str , str ]] | None = [] system_message: str | None = "" class TextItem (BaseModel ): text: str @app.post("/asr" async def ocr (audio_item: AudioItem ): audio_path = audio_item.audio_path if ("http" not in audio_path) and (not os.path.exists(audio_path)) and (len (audio_path) < 100 ): return {"code" : -1 , "audio" : audio_path, "meg" : "Audio Not Exists." } content = asr_model.audio2txt(audio_path) return {"code" : 0 , "content" : content} @app.post("/llm" async def llm (llm_item: LLMItem ): text = llm_item.text if (text is None ) or (text == "" ): return {"code" : -1 , "meg" : "Text is empty." } return_text = llm_model.chat(text, message=llm_item.message, system_message=llm_item.system_message) return {"code" : 0 , "content" : return_text} @app.post("/tts" async def tts (text_item: TextItem ): text = text_item.text if (text is None ) or (text == "" ): return {"code" : -1 , "meg" : "Text is empty." } audio_path = f"tmp/{gen_random_job_id()} .mp3" await tts_model(text, audio_path) audio_base64 = audio_to_base64(audio_path) os.remove(audio_path) return {"code" : 0 , "content" : audio_base64}
这个代码是使用FastAPI作为后端,编写了asr、llm、tts三个接口对外部提供服务。
FastAPI 是一个用于构建 Web API的现代 Python Web框架,近年来因其高性能 、易用性 和开发效率高 等特点,成为开发者首选的接口工具之一。
接下来在项目根目录创建一个start.sh文件,并在文件中输入以下内容。
1 /root/autodl-tmp/voice_dh/.venv/bin/gunicorn api:app -k uvicorn.workers.UvicornWorker --bind =0.0.0.0:6006 --worker-class=uvicorn.workers.UvicornWorker --worker-connections=1000 -w 1 --timeout 120
同样在这里我们也需要将这个服务托管到后台,首先开启一个tmux终端
然后运行start.sh脚本
1 cd /root/autodl-tmp/voice_dh && sh ./start.sh
服务开启成功
输入ctrl B+D托管终端。
现在,我们拥有了可以实现ASR、LLM和TTS的接口,并且接口是部署在AutoDL上的,只要经过端口映射,我们就可以直接把接口当成工具去使用。
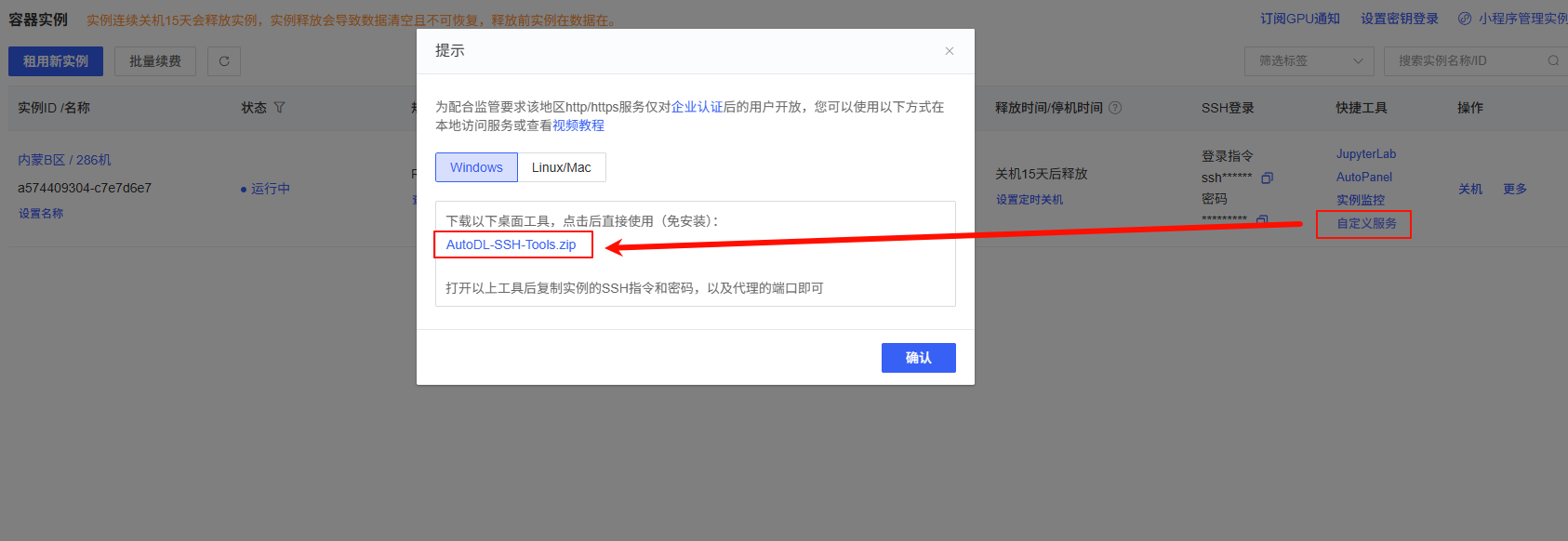
接口测试 默认的情况下,在AutoDL中开启的服务是无法对外提供服务的,需要在AutoDL官网下载端口映射工具。
下载完后,打开工具
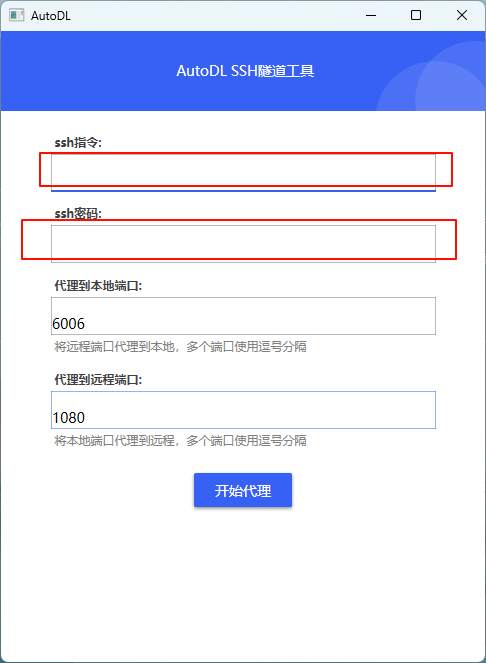
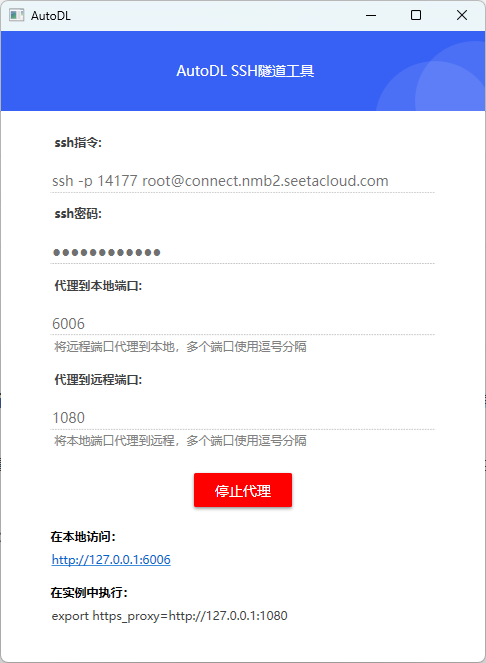
然后在AutoDL官网复制对应的信息到工具中。点击开启代理即可。
此时,我们就可以通过访问本地的6006端口,访问到AutoDL的6006端口,使用我们的服务。
ASR测试
TTS测试
LLM测试
语音数字人UI编写 前面我们已经部署好了,ASR、LLM和TTS相关接口,实际上关于语音数字人的核心代码我们已经编写完了。
所谓语音数字人无非就是:
用户发送音频到服务器 ->服务器使用ASR技术将音频转化为文字 -> 紧接着将转化好的文字发送到LLM中让大模型生成文字回答 -> 然后再将大模型生成的文字回答使用TTS技术转化为音频 -> 最后将生成好的音频返回给用户。
接下来,我们只需要编写适合用户使用的交互页面,接入我们上面编写的接口即可。所以这部分的代码可以不用在AutoDL上部署。
我们一共提供了2个版本给大家进行展示:
简单版:用户测试简单的对话,一问一答,大模型无记忆,页面只能存储单次对话记录。
完整版:可以执行复杂对话,支持多个客户端进行问答,且相互无干扰,大模型具备上下文记忆,页面可存储多条对话记录。
简单版 代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 import gradio as grimport requestsimport base64from utils.utils import gen_random_job_id, logger, audio_to_base64import osif not os.path.exists("tmp" ): os.makedirs("tmp" ) api_url = "http://localhost:6006" def base64_to_audio_file (base64_string, output_path ): audio_bytes = base64.b64decode(base64_string) with open (output_path, "wb" ) as f: f.write(audio_bytes) return output_path class AudioDH : def __init__ (self ): self.system_prompt = "你是minglog,是由骆明开发的聊天机器人。你擅长编写人工智能和大模型相关的代码,有丰富的项目开发经验。" def asr (self, audio_path ): api = f"{api_url} /asr" logger.info(f"ASR In: {audio_path} " ) resp = requests.post(api, json={"audio_path" : audio_to_base64(audio_path)}) if resp.status_code == 200 and resp.json().get("code" ) == 0 : text = resp.json().get("content" ) logger.info(f"ASR Out: {text} " ) else : raise gr.Error("ASR 出错,请检查ASR服务。" ) return text def llm (self, text, system_message, message ): api = f"{api_url} /llm" logger.info(f"LLM In: {text} " ) resp = requests.post(api, json={"text" : text, "system_message" : system_message, "message" : message}) if resp.status_code == 200 and resp.json().get("code" ) == 0 : resp_text = resp.json().get("content" ) logger.info(f"LLM Out: {resp_text} " ) else : raise gr.Error("LLM 出错,请检查LLM服务。" ) return resp_text def tts (self, text ): api = f"{api_url} /tts" logger.info(f"TTS In: {text} " ) resp = requests.post(api, json={"text" : text}) if resp.status_code == 200 and resp.json().get("code" ) == 0 : audio_base64 = resp.json().get("content" ) save_path = f"tmp/{gen_random_job_id()} .mp3" base64_to_audio_file(audio_base64, save_path) logger.info(f"TTS Out: {save_path} " ) return save_path else : raise gr.Error("TTS 出错,请检查TTS服务。" ) def respond (self, audio ): text = self.asr(audio) llm_text = self.llm(text, self.system_prompt, [])[0 ] return_audio = self.tts(llm_text) response1 = gr.Audio(value=audio, autoplay=False ) response2 = gr.Audio(value=return_audio, autoplay=True ) return [(response1, response2)], None def create_ui (self ): with gr.Blocks() as demo: chatbot = gr.Chatbot() with gr.Row(): audio_input = gr.Audio(sources="microphone" , type ="filepath" , label="上传音频" ) audio_input.stop_recording(fn=self.respond, inputs=[audio_input], outputs=[chatbot, audio_input]) return demo audio_dh = AudioDH() demo = audio_dh.create_ui() demo.launch(allowed_paths=["tmp" ])
该项目交互页面使用gradio编写,所以只需要按照gradio即可。这个代码依赖前面我们使用的utils.py文件,大家需要将该文件也准备好。
1 2 uv add gradio pip install gradio
这里使用uv工具和pip工具均可。
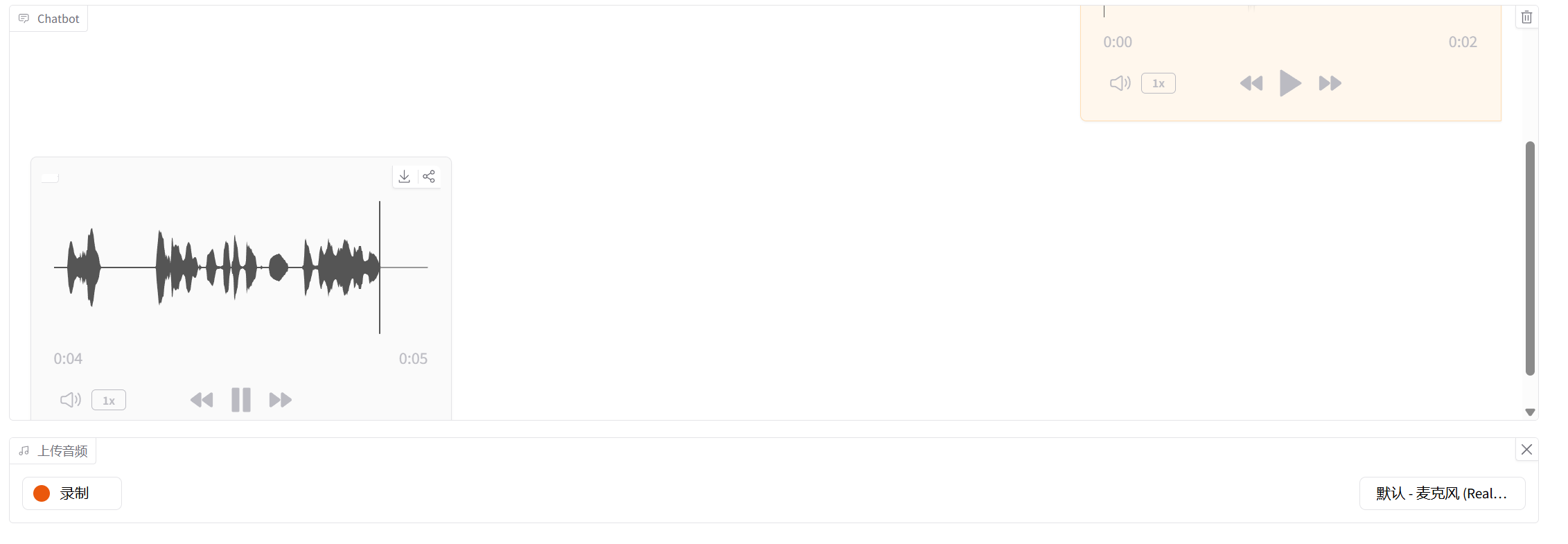
完整版 代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 import gradio as grimport requestsfrom utils.utils import gen_random_job_id, logger, base64_to_audio_file, audio_to_base64import osif not os.path.exists("tmp" ): os.makedirs("tmp" ) api_url = "http://localhost:6006" class AudioDH : def __init__ (self ): self.system_prompt = "你是minglog,是由骆明开发的聊天机器人。你擅长编写人工智能和大模型相关的代码,有丰富的项目开发经验。" def asr (self, audio_path ): api = f"{api_url} /asr" logger.info(f"ASR In: {audio_path} " ) resp = requests.post(api, json={"audio_path" : audio_to_base64(audio_path)}) if resp.status_code == 200 and resp.json().get("code" ) == 0 : text = resp.json().get("content" ) logger.info(f"ASR Out: {text} " ) print ("-" * 20 ) else : raise gr.Error("ASR 出错,请检查ASR服务。" ) return text def llm (self, text, system_message, message ): api = f"{api_url} /llm" logger.info(f"LLM In: {text} " ) resp = requests.post(api, json={"text" : text, "system_message" : system_message, "message" : message}) if resp.status_code == 200 and resp.json().get("code" ) == 0 : resp_text = resp.json().get("content" ) logger.info(f"LLM Out: {resp_text} " ) print ("-" * 20 ) else : raise gr.Error("LLM 出错,请检查LLM服务。" ) return resp_text def tts (self, text ): api = f"{api_url} /tts" logger.info(f"TTS In: {text} " ) resp = requests.post(api, json={"text" : text}) if resp.status_code == 200 and resp.json().get("code" ) == 0 : audio_base64 = resp.json().get("content" ) save_path = f"tmp/{gen_random_job_id()} .mp3" base64_to_audio_file(audio_base64, save_path) logger.info(f"TTS Out: {save_path} " ) print ("-" * 20 ) return save_path else : raise gr.Error("TTS 出错,请检查TTS服务。" ) def respond (self, audio, history, chat_ui ): text = self.asr(audio) if history is None : history = [] if chat_ui is None : chat_ui = [] llm_text = self.llm(text, self.system_prompt, history)[0 ] history.append({"role" : "user" , "content" : text}) history.append({"role" : "assistant" , "content" : llm_text}) return_audio = self.tts(llm_text) user_html = f"<p>🧑💬: {text} </p><audio controls src='http://localhost:7860/gradio_api/file={audio} '></audio>" bot_html = f"<p>🤖: {llm_text} </p><audio controls autoplay src='http://localhost:7860/gradio_api/file={return_audio} '></audio>" chat_ui.append((user_html, bot_html)) return chat_ui, history, chat_ui, None def create_ui (self ): with gr.Blocks() as demo: chatbot = gr.Chatbot() audio_input = gr.Audio(sources="microphone" , type ="filepath" , label="上传音频" ) history_state = gr.State(value=[]) chat_ui_state = gr.State(value=[]) audio_input.stop_recording(fn=self.respond, inputs=[audio_input, history_state, chat_ui_state], outputs=[chatbot, history_state, chat_ui_state, audio_input]) return demo audio_dh = AudioDH() demo = audio_dh.create_ui() demo.launch(allowed_paths=["tmp" ])
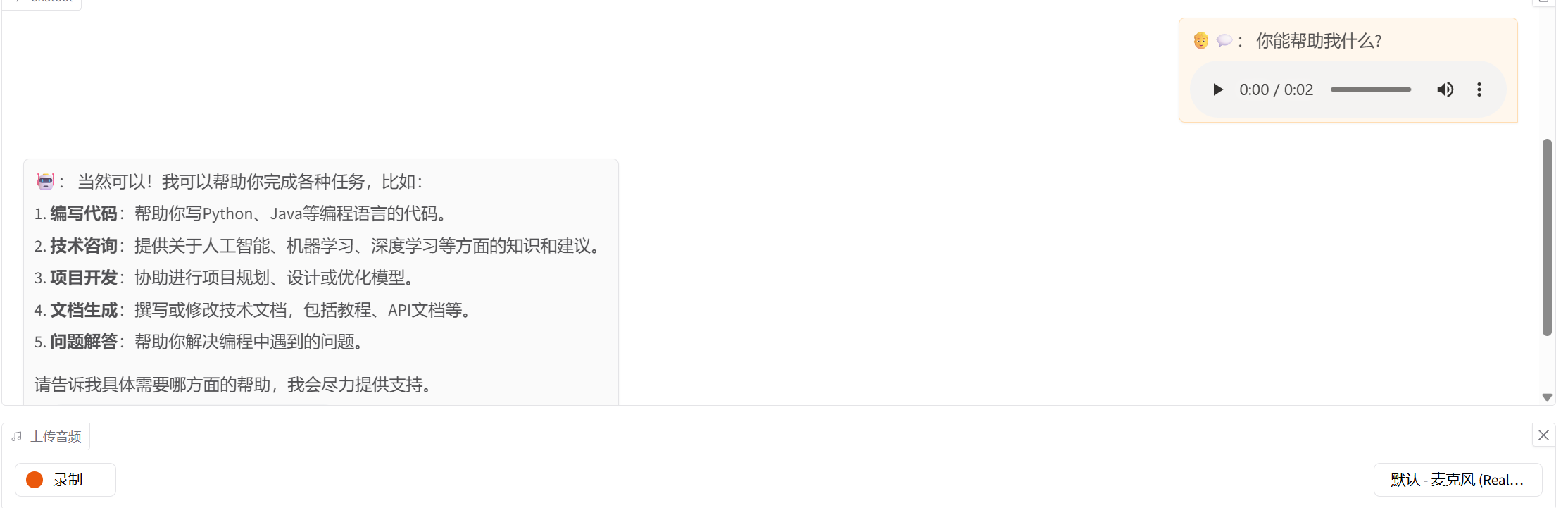
演示效果:
项目地址 课程项目已在gitee开源,大家可以直接使用已有项目进行克隆和部署。
项目地址:https://gitee.com/ming_log/voice_dt