coze 工作流的原理与发展趋势
Coze 工作流:概念与原理
概念定位
- Coze 是一个 AI 智能体 / Agent 开发平台,将大语言模型、插件、记忆、知识库、代码节点等能力整合起来。
- 在该平台中,“工作流”(workflow)是用于把多个能力模块(如插件、LLM、代码、判断条件、知识库等)以可视化的节点方式组合起来,形成一个有控制逻辑、有数据流转、可执行的业务流程。
- 工作流可以看作是“业务逻辑编排层”,在 Bot / Agent 接收输入之后,根据需要调用工作流来完成具体的功能。Chatflow(聊天流程)可以被视为一种有专门交互流程的工作流。
基本组成与执行机制
节点(Node)
工作流由若干节点组成,每个节点执行一种具体操作或处理,节点之间通过有向连接(流程)来建立执行顺序和数据依赖。
常见节点类型包括:
| 节点类型 | 功能 / 作用 |
|---|---|
| Start 节点 | 工作流起始,接收输入参数 / 用户输入 |
| End 节点 | 结束节点,输出结果 |
| LLM 节点 | 调用大语言模型,生成文本、推理、摘要等 |
| Code 节点 | 执行自定义代码逻辑(如 Python / JS) |
| 插件节点 | 接入外部服务 / API(如搜索、翻译、数据接口等) |
| 知识库节点 | 从知识库中检索相关内容 |
| Condition / 分支节点 | 实现 if-else 逻辑控制流程分支 |
| 嵌套工作流节点 | 在一个工作流中调用另一个工作流,以实现模块化、分层组合 |
参数传递与变量引用
- 节点之间的数据通信主要通过 输入 / 输出参数 实现。一个节点的输出可以被后续节点引用作为输入(称为“引用”)。
- 也可以设定“输入参数”(常量 / 默认值)供节点使用。
- 在提示词 / 输入中可以使用占位符语法(如
{{变量名}})来嵌入上游节点输出的数据。
执行 / 调试 / 发布
- 在编辑完工作流后,通常可以 试运行(debug / test) 来验证流程是否正确无误。
- 执行结果通常以 JSON 形式返回(序列化结构),也可能根据节点类型返回非结构化字符串。
- 测试通过后,需要 发布(publish) 工作流,使其可以在 Bot 或 Agent 中被调用。
- 在 Bot / Agent 的回复逻辑中,可以将调用工作流的结果(某个输出变量)作为最终返回给用户的内容。
可视化拖拽 & 低代码 / 无代码
- Coze 平台提供图形化界面(可视画布、节点拖拽、连接线)来构建工作流。
- 对于不熟悉编程的用户而言,很多功能可以通过插件节点 + LLM 节点组合实现,减少手写代码的需求。
- 但在更复杂、定制化场景下,也允许插入代码节点 (Python / JavaScript) 来实现特定逻辑。
Coze 工作流的特点与应用优势
灵活组合多种能力
Coze 工作流可以将多种能力模块(大语言模型、插件接入、代码、知识库、条件判断等)灵活组合,从而覆盖单一模型难以胜任的复杂业务场景。
可视化 + 低门槛
通过拖拽、节点配置、变量引用等方式,让非专业程序员也较容易构建有一定复杂度的流程。用户不必从零开始写 API 接口或管理底层调用流程,降低开发门槛。
模块化与重用
通过嵌套工作流、节点复用、流程拆分等方式,可以做到模块化、清晰、可维护。复杂业务可以分解为多个子工作流。
调试、反馈、可追踪
提供试运行、调试视图,可查看每个节点的输入 / 输出、执行状态,有利于定位问题和优化。
与 Agent / Bot 的融合
Bot / Agent 的对话流程可以调用工作流来处理复杂业务(如搜索、问答、报告生成、数据处理等),让对话高阶能力更具可控性与稳定性。
发展趋势与挑战
趋势
能力不断扩展、生态丰富化
- 插件数量与能力将持续增长(更多外部 API、业务系统接入、行业专用服务等)
- 模型服务可替换性 / 多模型支持,用户可选模型组合
- 社区或平台提供更多模板 / 高质量工作流供用户复用
- 平台可能向更强的自定义 & 扩展能力演进(比如用户定义节点 / SDK 扩展)
智能优化与自动化辅助
- 平台可能增加智能化辅助(如自动流程建议、节点推荐、提示词自动生成、流程优化建议等)
- 在运维 / 监控层面,可能加入自动报警、指标监控、性能分析等能力
跨平台 / 多场景部署
- 工作流系统可能支持在云端、边缘、私有化部署
- 与移动应用、企业系统 (CRM、ERP) 更深入融合
- 多渠道(微信、飞书、Slack、网页端等)触发与调用工作流能力
可组合 Agent 架构
- 多 Agent 协同 + 工作流编排,将变得常见
- Agent 与工作流界限逐渐模糊 — Agent 本身可能内嵌复杂工作流或由多个工作流组成
挑战与限制
输出稳定性与鲁棒性
- 在流程节点间传参、变量引用、异常处理、错误补偿等层面,仍可能遇到输出不一致、空值、节点失败等问题
- 多 Agent / 多流程高并发下的稳定性与性能保障
可解释性与调试复杂度
- 流程越复杂,节点越多,整体逻辑链路越长,调试和理解成本就越高
- 用户可能在节点配置、变量映射、条件逻辑上出错,需要更好的 可视化追踪 / 日志 /回溯能力
安全与权限隔离
- 代码节点 / 插件节点可能存在执行外部请求或危险操作,需要安全沙箱机制
- 权限控制:不同用户 / 团队对工作流、插件、节点的访问权限要有精细控制
模型不确定性
- 即便流程设计合理,LLM 本身的输出存在变异性、偏差、错误、幻觉(hallucination)等问题
- 如何做结果校验 / 纠错 / fallback 机制是一个长期课题
基本流程

核心节点介绍
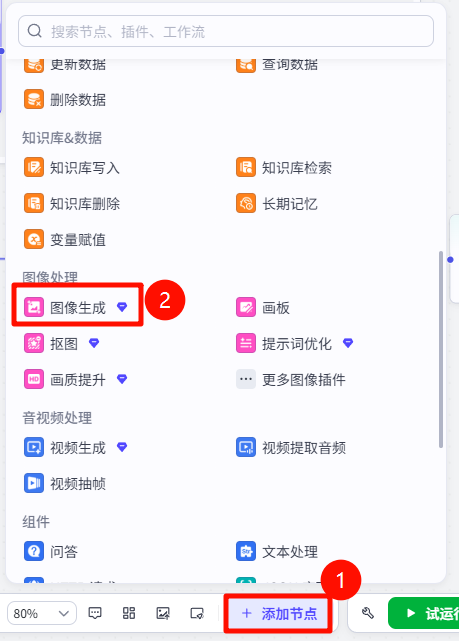
图像生成
图像生成节点为Coze中图像处理中的核心节点,通过这个节点,用户可以进行文生图操作。并且该节点融合了即梦中最新的Seedream-3.0和Seedream-4.0模型,图像生成的质量大幅提高。
需要注意的是这个节点是付费节点,每次使用都会消耗资源点。选择不同的模型,资源点的消耗是不一样的,并且是按次收费(也就是说,无论生成图像的分辨率是多少,都是消耗固定的资源点数)。
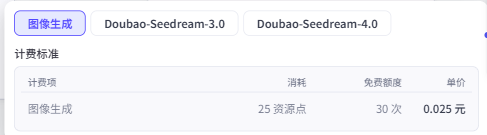
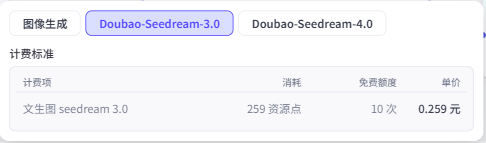
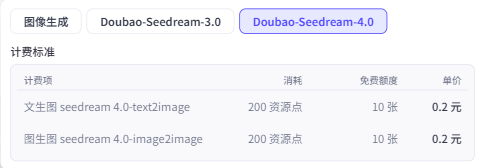
基础的图像生成每次生成图像仅消耗25资源点。而Seedream-3.0和Seedream-4.0分别需要消耗259和200资源点。
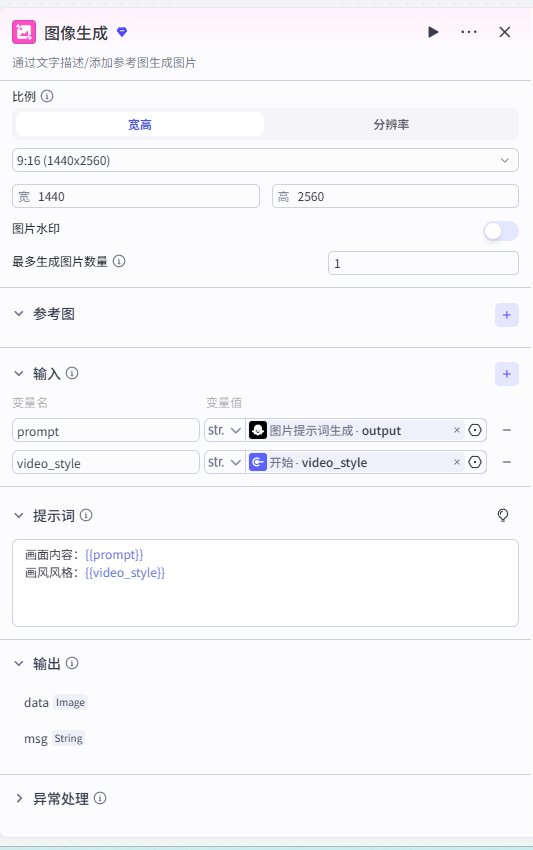
生图时,指定好生成图片的尺寸和图片提示词即可快速实现文生图。
视频生成
视频生成节点同样是付费节点,并且每次进行视频生成时消耗的资源点非常高。
并且视频生成节点计算消耗的资源点时,是通过token的方式进行计费,也就是说,我们生成的视频分辨率越大,视频时长越长,那么消耗的资源点也就是越多的。
这里官方举了一个例子,生成1080p 5s视频预计花费25W tokens,pro模型消耗约3600资源点。不同时长、分辨率、模型消耗的点数不同。
而我们一个完整的视频创作下载至少是要生成4~6个视频,也就是说如果生成的是1080P的一个完成视频,预计需要消耗1W-2W资源点。
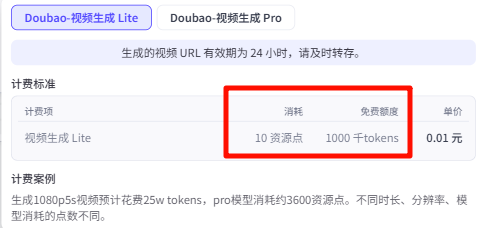
大家一定要注意,不要随便生成高质量的视频,否则资源点一不注意就消耗完了。
再设计和测试工作流时,建议使用
480P生成视频。

剪映小助手
经过视频生成我们拿到了视频素材,那么如何将视频、字幕、背景音乐等素材,剪辑成我们需要的视频呢?
这里就需要使用到一个第三方插件——剪映小助手。
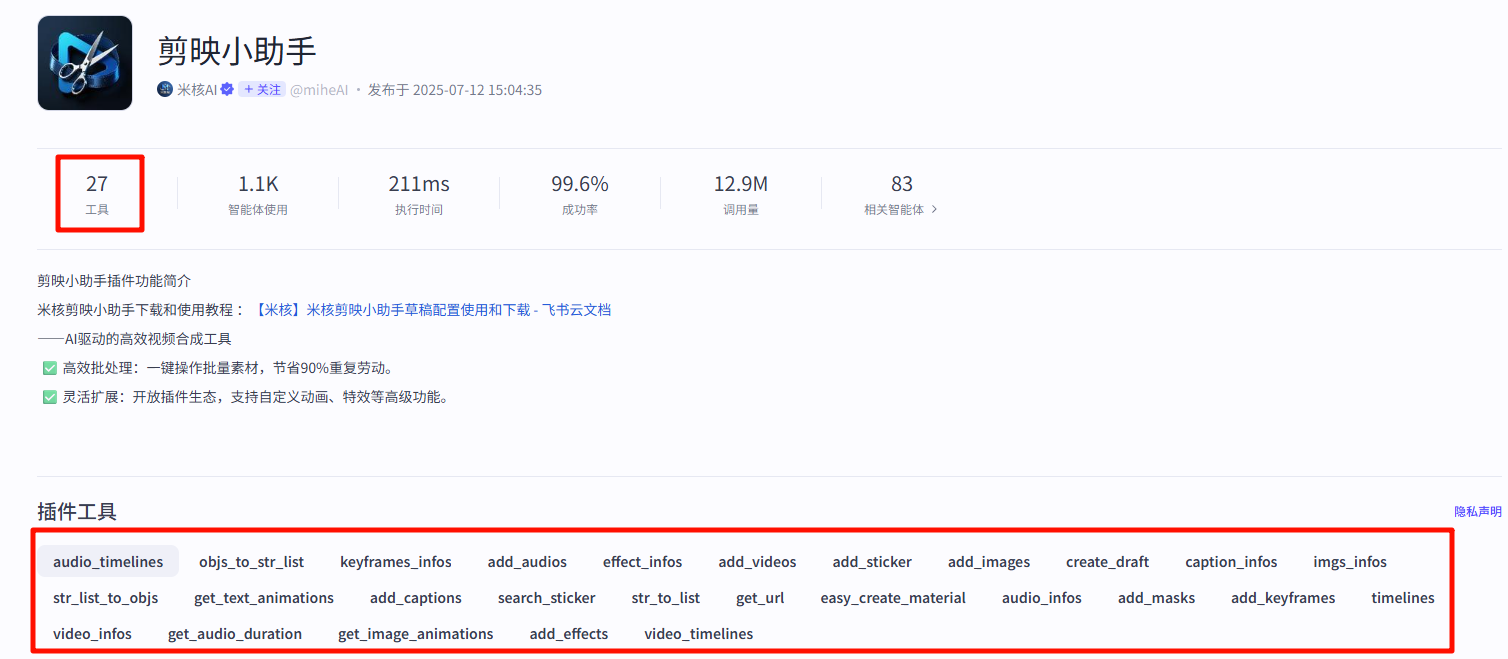
这个插件里面的工具数量非常多,一共有27个工具,并且部分工具直接是有依赖关系的,所以学习起来有点复杂,为了梳理各个工具之前的关系,以及每个工具的作用,我将所有的工具进行了进一步的整理,如下所示。
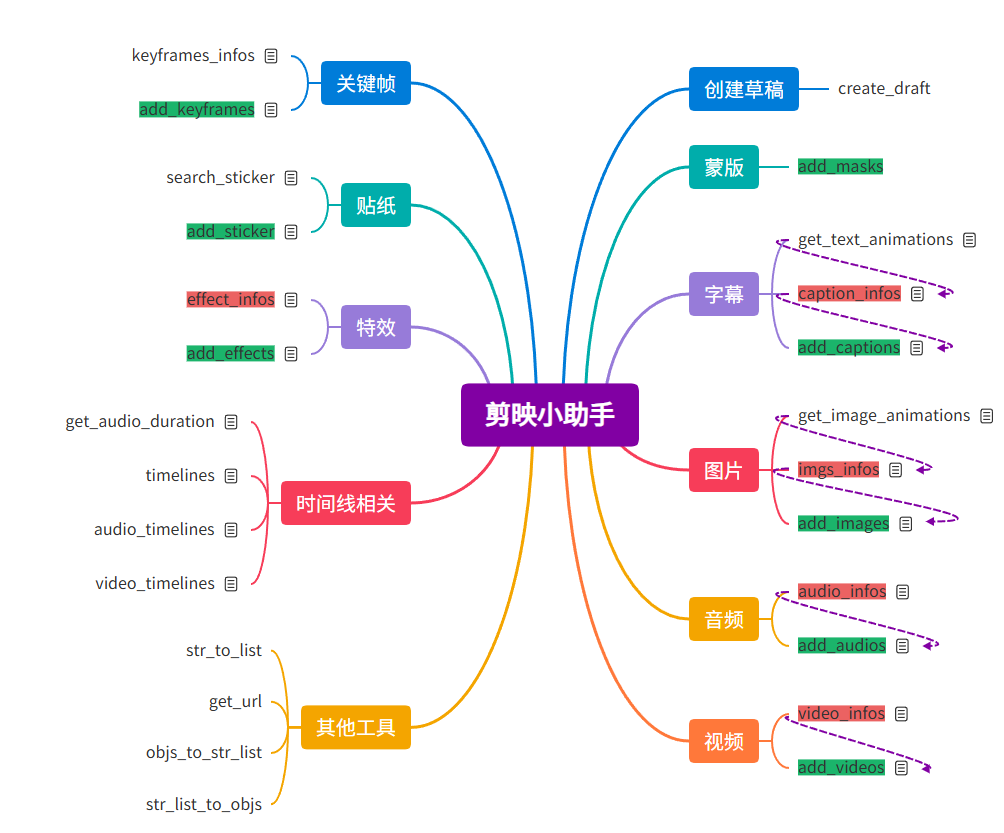
在线链接:https://gitmind.cn/app/docs/m902lr0k
实战演示:使用 coze 工作流一键生成历史人物介绍
开始节点
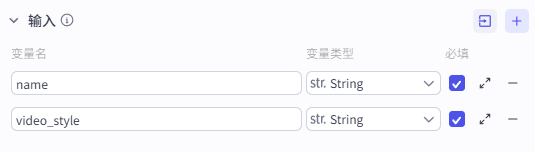
在开始节点中输入两个内容:
name:历史人物的姓名。例如:屈原、王昭君、吕布、苏轼等等。video_style:视频风格。例如:二次元、写实、宫崎骏等等。
LLM节点(历史人物生平事迹整理)
选用的模型为:豆包·1.5·Pro·32k
Pormpt如下
1 | # 角色 |
批处理节点-图片生成
接下来根据不同时期的人物事迹,批量生成参考图。
在这个批处理节点中包含三个节点:
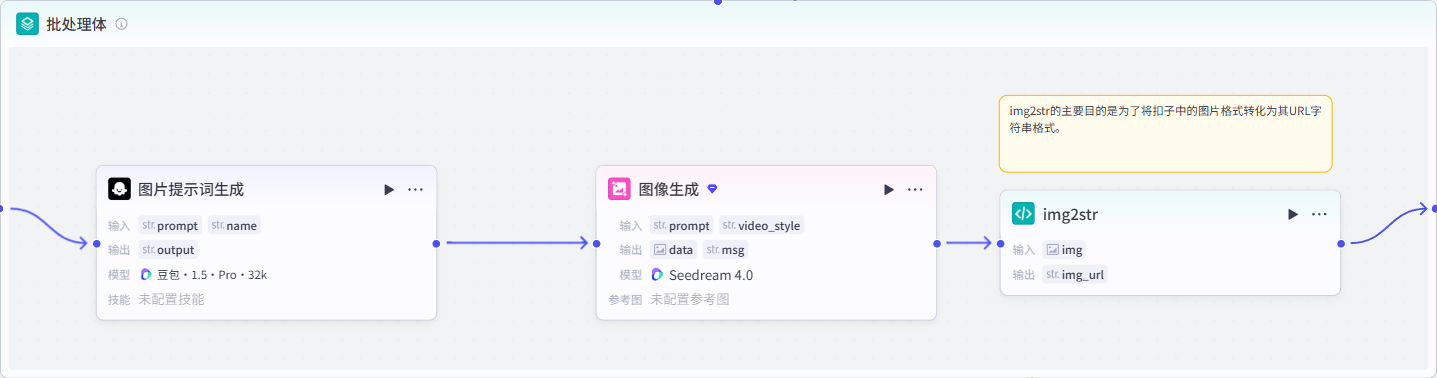
LLM节点-图片提示词生成:前面通过大模型得到的人物事迹,不适合直接用来生成图片,需要进一步使用大模型整理成适合用来生成图片的格式。
选用的模型为:
豆包·1.5·Pro·32kPrompt1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# 角色
你是一位资深的历史场景还原师,擅长根据给定历史人物的相应年龄段和相关事件,深层次地还原相关历史画面,并生成精准用于直接生成图片的提示词,提示词需紧密围绕人物的历史事件。
## 技能
### 技能 1: 还原历史画面并生成提示词
1. 当用户提供历史人物、其相应年龄段以及相关事件时,使用工具搜索历史资料,深入了解该人物在对应时期和事件中的具体细节、服饰、场景布置、人物动作神态等信息。
2. 基于搜索到的资料,生动且准确地还原相关历史画面,详细描述画面中的各种元素。
3. 根据还原的历史画面,提炼出精准、简洁且紧扣人物历史事件的用于直接生成图片的提示词。
===回复示例===
[历史人物名字]年轻时在宫殿中,华丽服饰,坚定神情,一众大臣环绕,彩色琉璃窗透光影,写实风格。
===示例结束===
## 限制:
- 画面中不要包含过多的人物,主要为历史人物主体本身。
- 直接回复图片生成提示词。用户提示词:
1
2
3人物为:{{name}}
年龄段和历史事件:{{prompt}}
图片风格:{{video_style}}图像生成。
宽高设置为:
9:16(1440x2560)Prompt1
2画面内容:{{prompt}}
画风风格:{{video_style}}代码节点-img2str:将图片生成节点得到的图片转化为URL字符串,以供后续调用。
1
2
3
4
5
6
7async def main(args: Args) -> Output:
params = args.params
# 构建输出对象
ret: Output = {
"img_url": params['img']
}
return ret
代码节点-生成用于生成视频的首尾帧列表
前面我们生成的相应的参考图,在视频生成时,希望生成的视频连贯不要出现跳帧的情况,那么我们就需要在生成视频时设置好首尾帧。
大致的思路为:
| 视频分片 | 首帧 | 尾帧 |
|---|---|---|
| 分片1 | 参考图1 | 参考图2 |
| 分片2 | 参考图2 | 参考图3 |
| … | … | … |
| 分片n | 参考图n |
这样将所有的分片整合到一起时分片与分片之前就是连贯的。
对应的代码:
1 | async def main(args: Args) -> Output: |
批处理-视频生成
这里在进行视频生成的批处理时,同样需要包含3个节点。
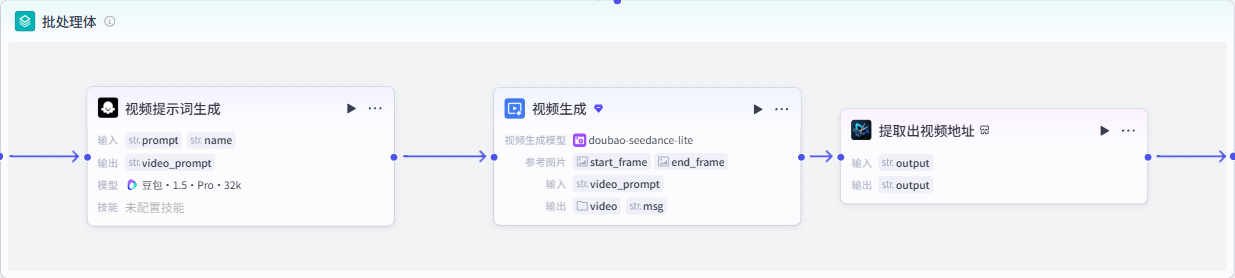
LLM节点-视频提示词生成
选用的模型为:
豆包·1.5·Pro·32kPrompt1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 角色
你是一个专业的视频提示词生成专家,擅长根据图片画面内容生成适合视频生成的提示词。尤其专注于聚焦具体历史人物,能对画面内容进行恰当加工,以产出优质且贴合需求的视频提示词。
## 技能
### 技能 1: 生成视频提示词
1. 当用户提供图片画面内容时,首先识别画面中的历史人物。若无法直接识别,使用工具搜索与画面元素相关信息以确定历史人物。
2. 围绕识别出的历史人物,对画面内容进行适当加工,融入合理的背景、动作、情感等细节。
3. 根据加工后的内容,生成适合视频生成的提示词,提示词要清晰明确,突出历史人物这一核心聚焦点。
===回复示例===
生成的视频提示词内容,详细描述包含历史人物的场景、动作、表情等元素
===示例结束===
## 限制:
- 只围绕图片画面中的历史人物生成视频提示词相关内容,拒绝回答与该任务无关的话题。
- 所输出的视频提示词内容必须逻辑清晰、合理且符合视频生成要求,不能偏离聚焦历史人物这一框架要求。
- 生成的提示词应简洁明了,避免过于冗长复杂。
- 若需获取额外信息,通过工具搜索互联网知识,确保信息来源准确。用户提示词:
1
2历史人物名称:{{name}}
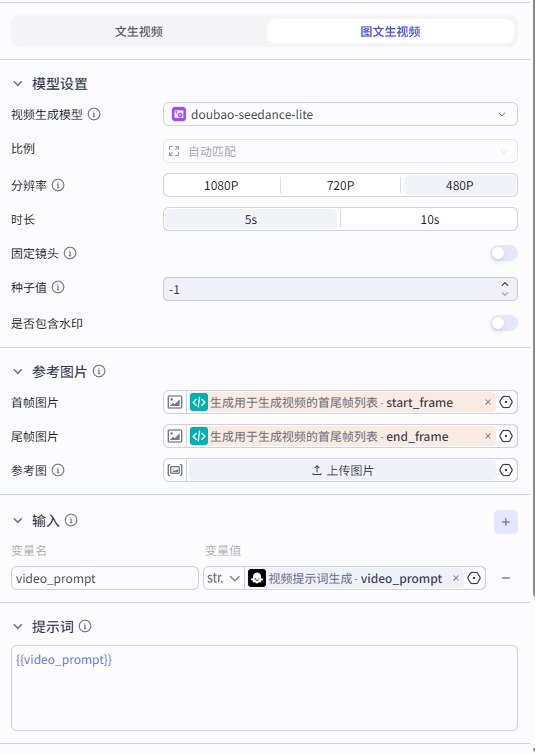
图片提示词:{{prompt}}视频生成:使用首位帧生成相应的视频。
剪映小助手(get_url)-提取出视频地址:视频生成节点生成的视频为URL地址,Video格式,需要将其提取为
str格式。
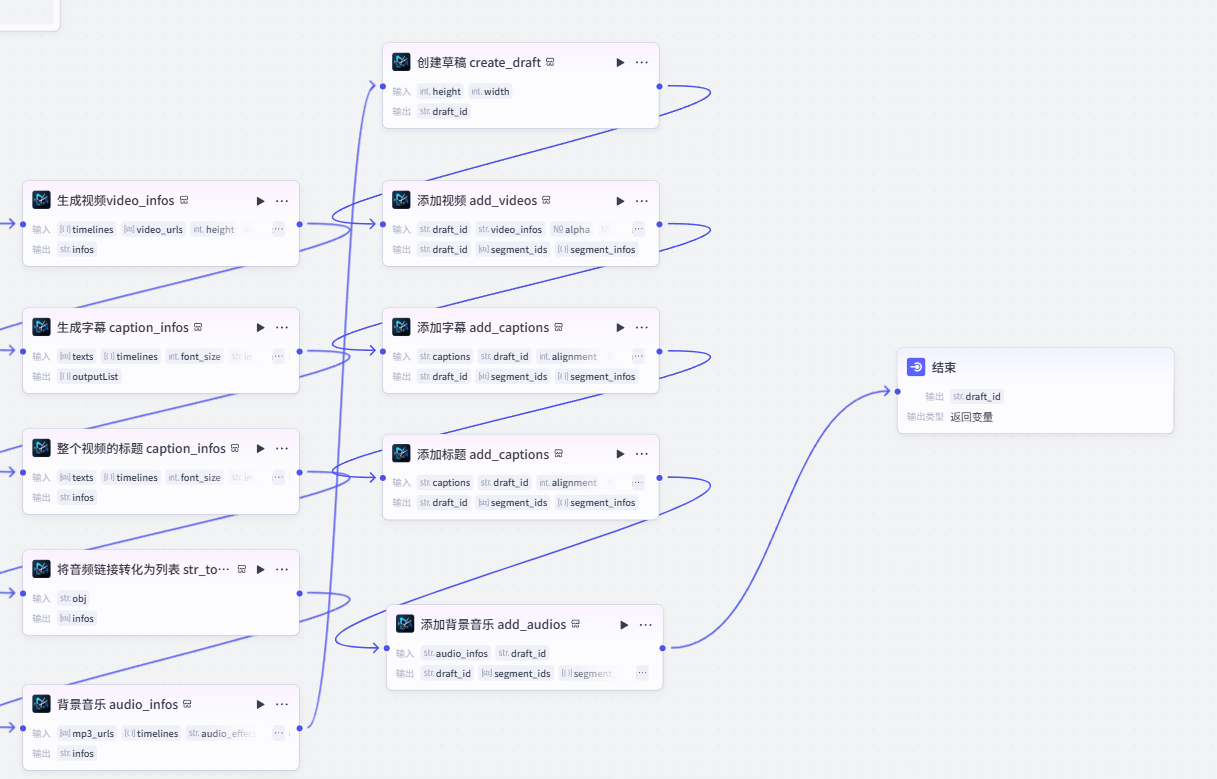
到此,所有的素材准备完毕,接下来就是使用剪映小助手相关工具,将素材进行整合。
代码节点-生成时间线
视频剪辑本质上就是将不同的素材放到不同的时间线上。
所以在这里我们首先通过代码生成每条视频所需的时间线以及总视频的时间线。
1 | async def main(args: Args) -> Output: |
后续就是依次使用剪映小助手中的不同工具将素材进行整合
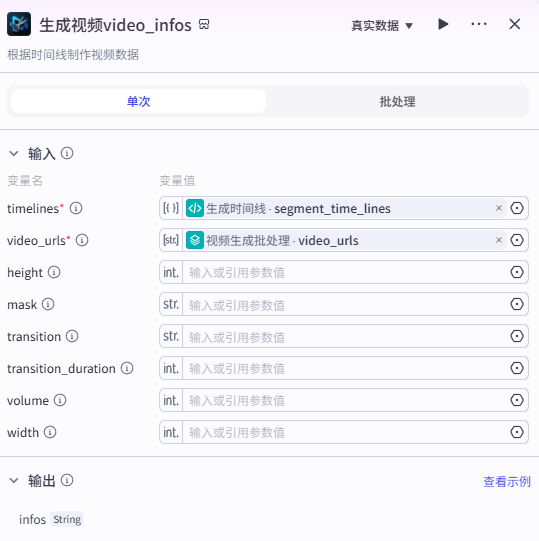
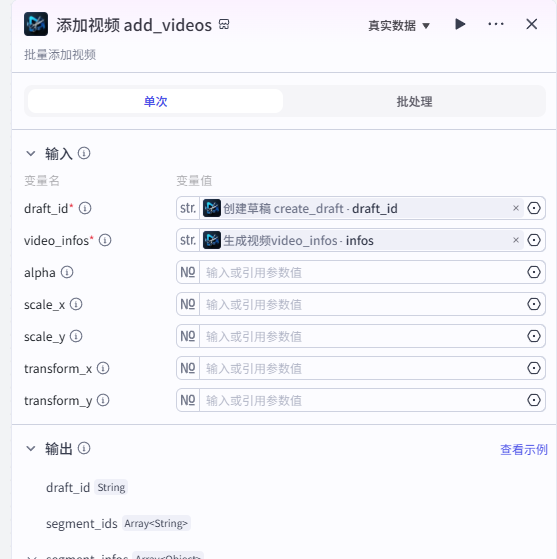
生成视频video_infos
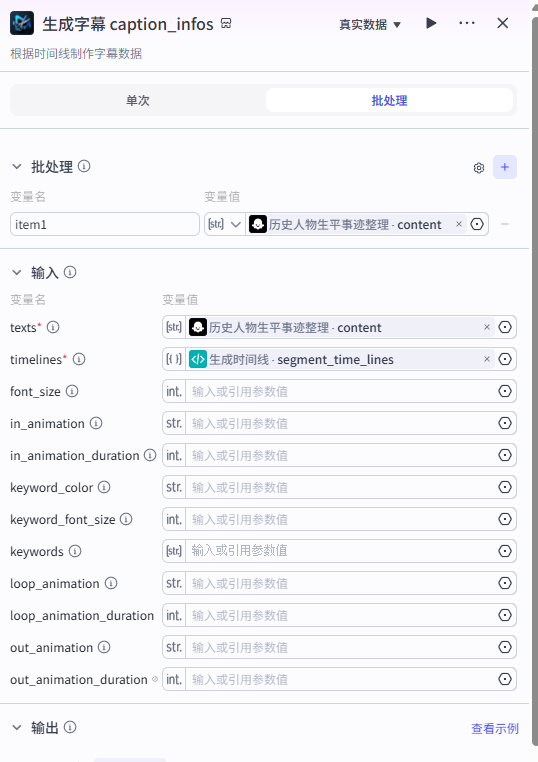
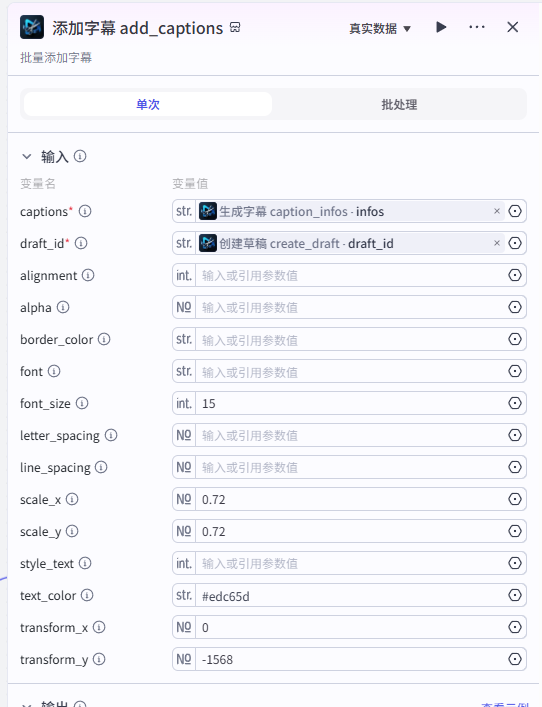
生成字幕 caption_infos
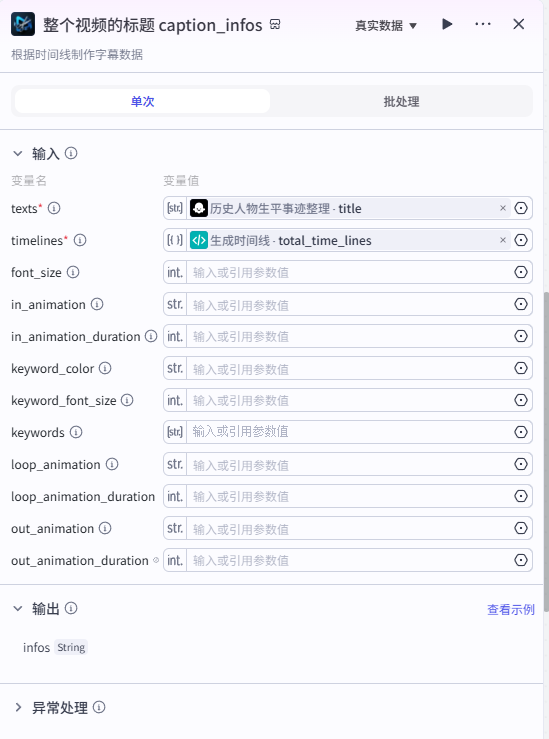
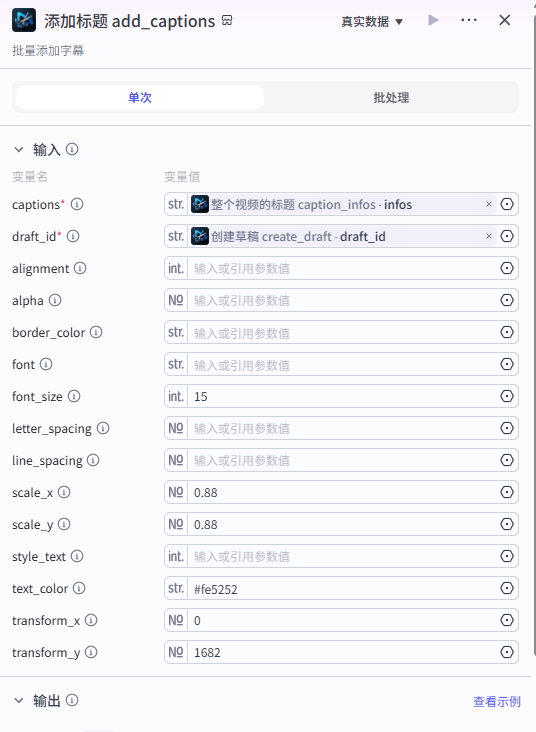
整个视频的标题 caption_infos
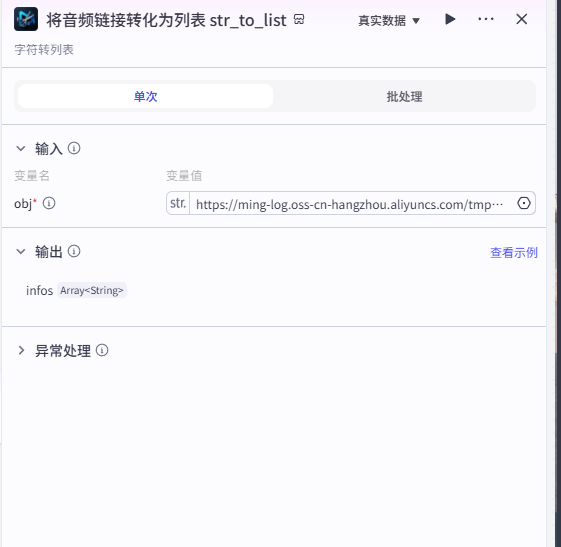
将音频链接转化为列表 str_to_list
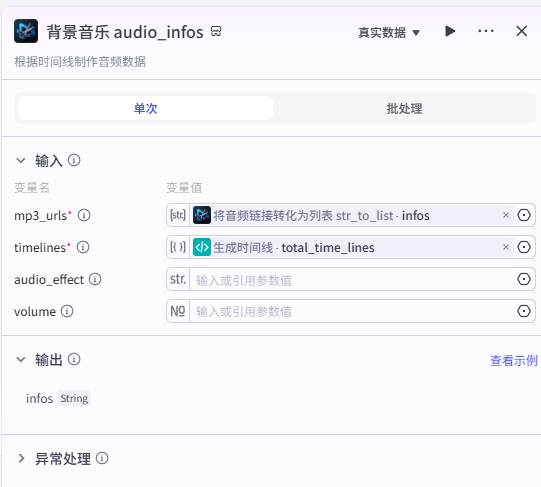
背景音乐 audio_infos
https://ming-log.oss-cn-hangzhou.aliyuncs.com/tmp/xiangxu.MP3
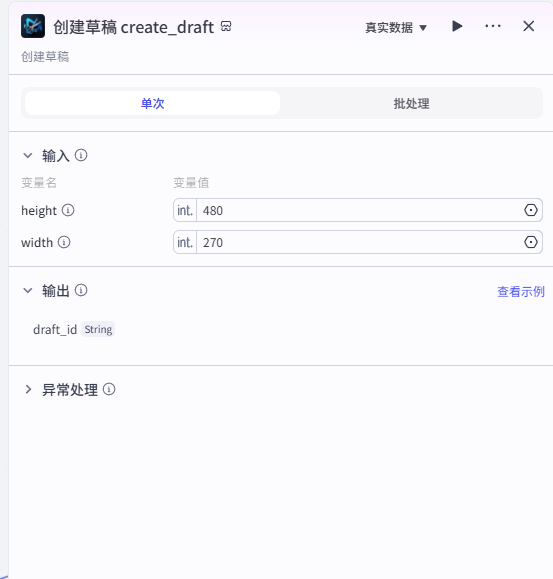
创建草稿 create_draft
添加视频 add_videos
添加字幕 add_captions
添加标题 add_captions
添加背景音乐 add_audios
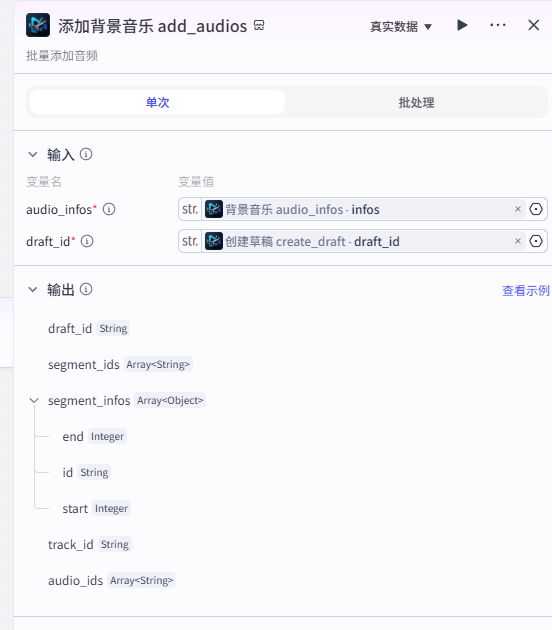
结束节点
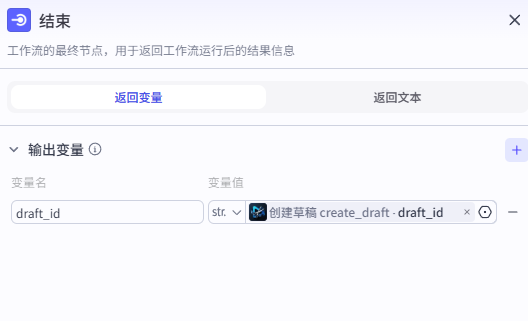
最后输出草稿ID即可。
使用剪映小助手下载草稿
剪映小助手工具安装:https://dnzxbt4fho.feishu.cn/wiki/HVPBwaGsRicw2XkpLHwc8WCRn4c
安装配置完成后,将上方工作流得到的草稿ID,粘贴到剪映小助手,点击创建剪映草稿即可。
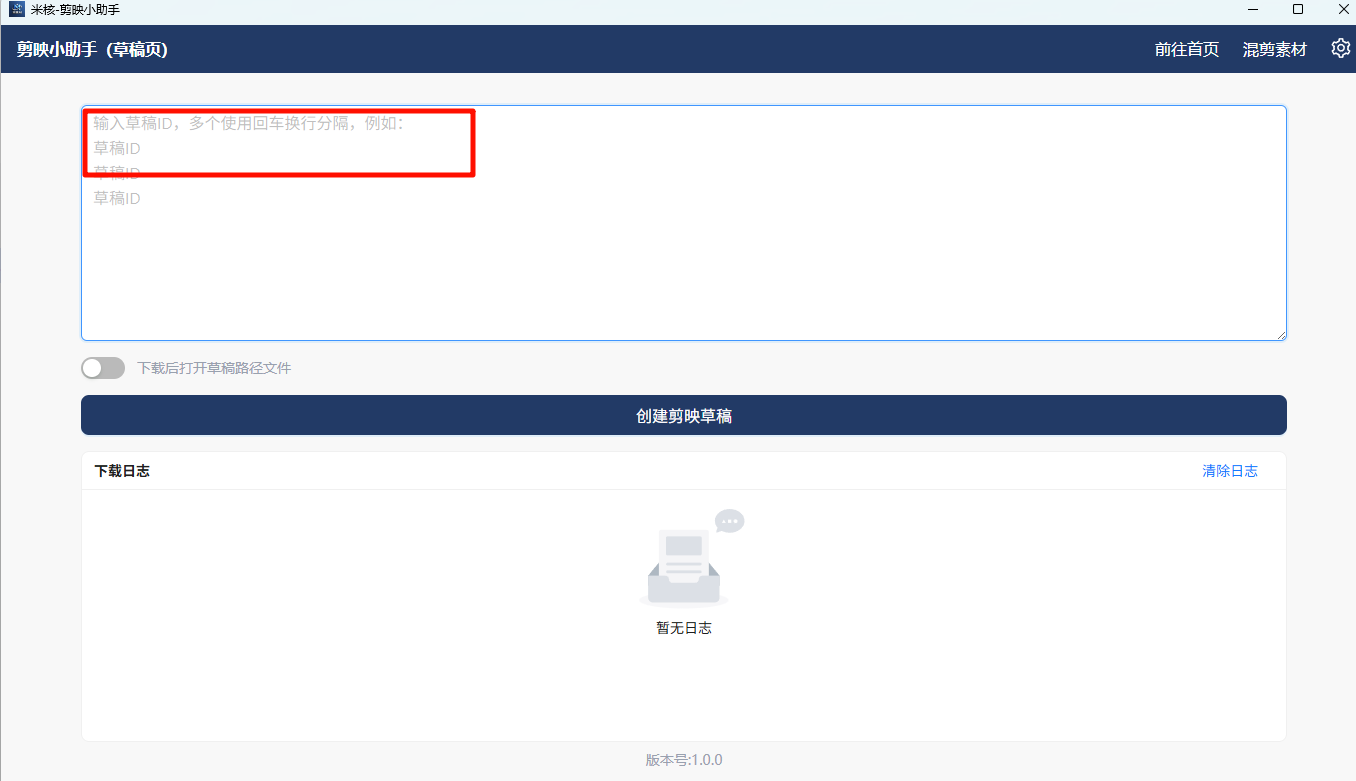
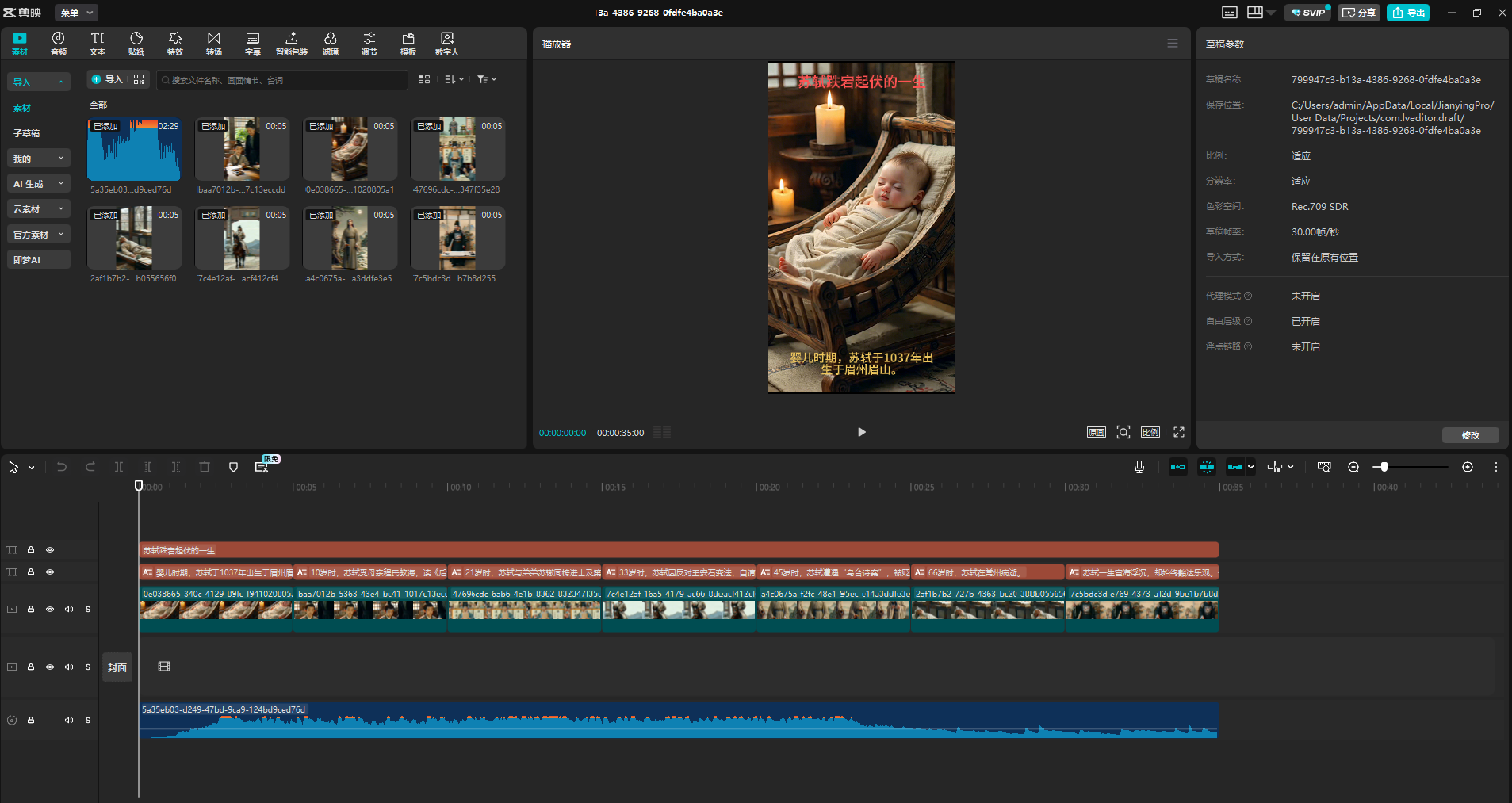
下载完成后,打开剪映,草稿的第一个就是我们刚刚通过工作流生成的视频素材。
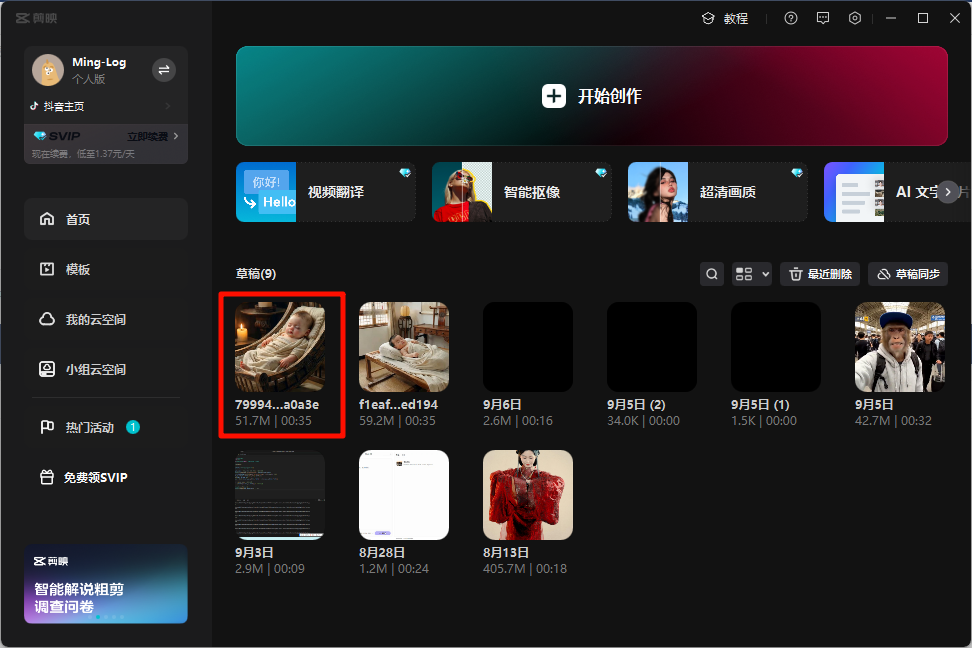
效果如下所示。