AutoDL平台介绍与使用展示
AutoDL平台介绍
AutoDL 是一个在线算力租赁与模型部署平台,提供简便的 GPU 云主机、JupyterLab 环境、端口映射、公网访问、文件传输等能力,广泛用于:
- 快速搭建
LLM推理环境(如Ollama、LMDeploy) - 开发 AI 应用(如
LangChain、Gradio Web UI) - 部署私有大模型(如
DeepSeek、Qwen、Baichuan等)
它面向的用户包括:
- 无
GPU的开发者 - 希望快速部署实验环境的科研人员
- 对私有化部署有一定隔离需求的企业用户
使用展示
账号注册
首先进入官网:https://www.autodl.com/home ,完成注册和充值。
算力租赁
接下来就是租赁服务器,租赁服务器的步骤非常简单,点击菜单栏中的算力市场。

在算力市场中就可以看到,可以租赁的算力以及对应的价格。为了方便大家快速找到自己想要的算力,AutoDL对不同的GPU型号进行的分区,这样我们就可以快速找到我们想要的GPU。
例如,现在我想在西北B区租赁一个5090显卡,那么就需要先点击西北B区,勾选5090这个GPU型号。【由于共享的镜像在西北地区,租赁西北地区的算力,容器的启动速度更快。】
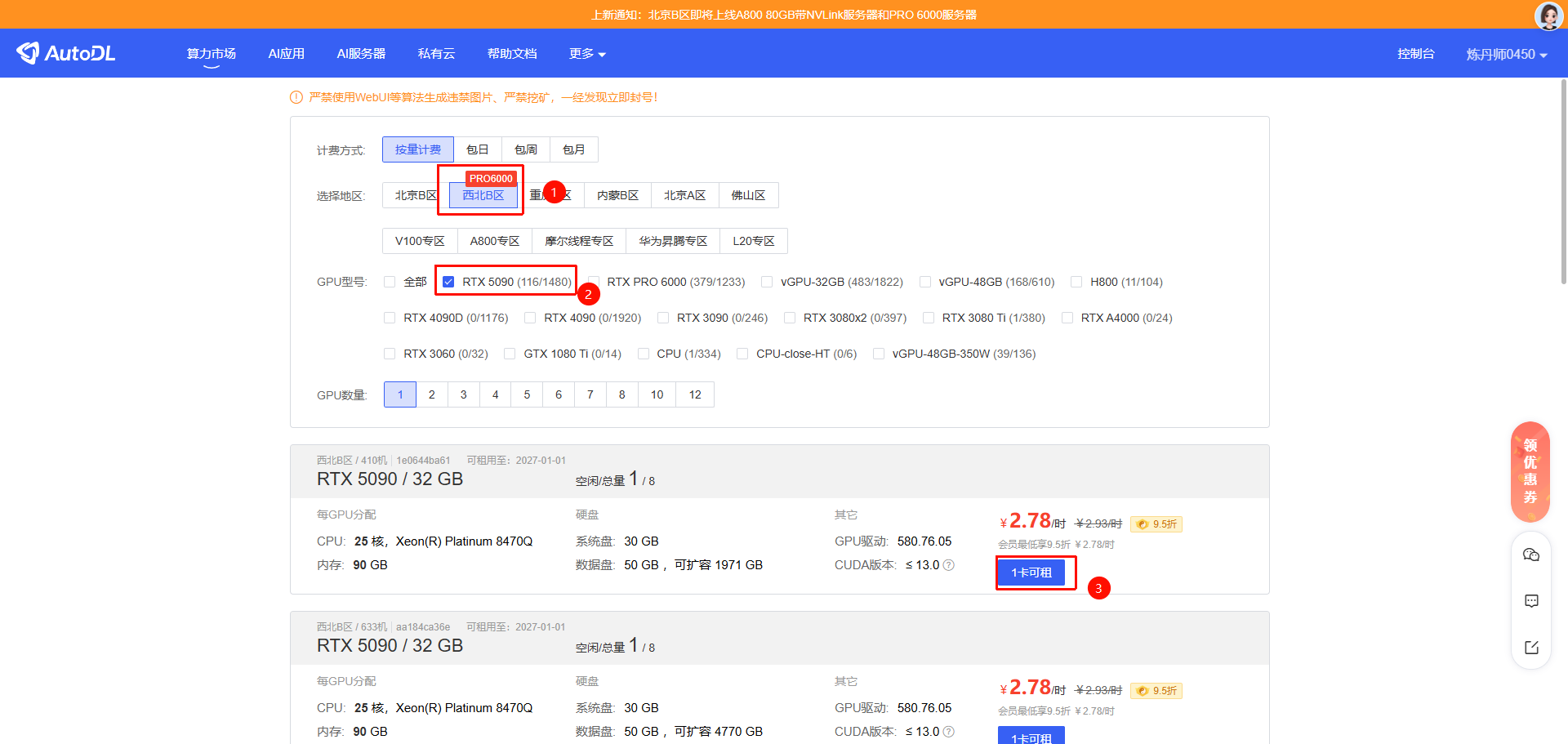
算力租赁时,计费方式有4种方式可供选择
- 按量计费:选择按量计费,价格发生变动以实例开机时的价格为准。
- 包日:一天(24小时)使用时间。
- 包周:一周使用时间。
- 包月:一个月使用时间。
如果不是长期使用建议选择按量付费即可。
选择好合适的计费方式后,接下来就开始选择主机相关的硬件配置。
在硬件配置中根据自己的实际情况,选择GPU卡的数量和数据盘的大小。
GPU卡的数量一般选择单卡即可。数据盘默认是有50G的空间,如果空间不够的话就需要付费购买额外的数据盘空间,付费数据盘将按 0.0070元/日/GB在每日24点进行扣款(无论实例是否关机)。
最后选择合适的镜像创建服务器。
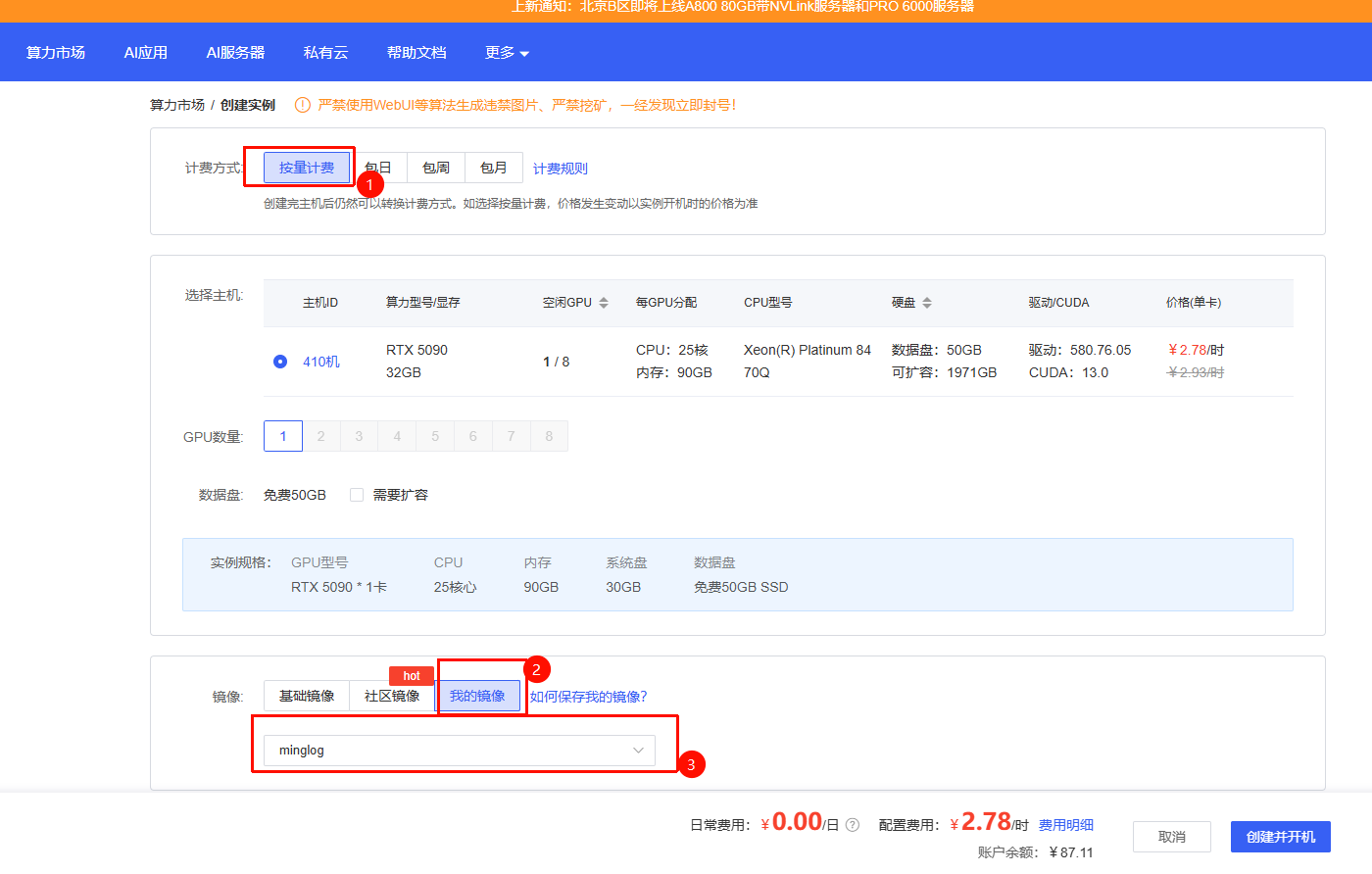
一切准备就绪后,点击创建并开机,这样我们的容器实例就创建好了。
创建好后,页面会自动跳转到【控制台】->【容器实例】目录,在该目录中会展示你创建的所有容器实例。
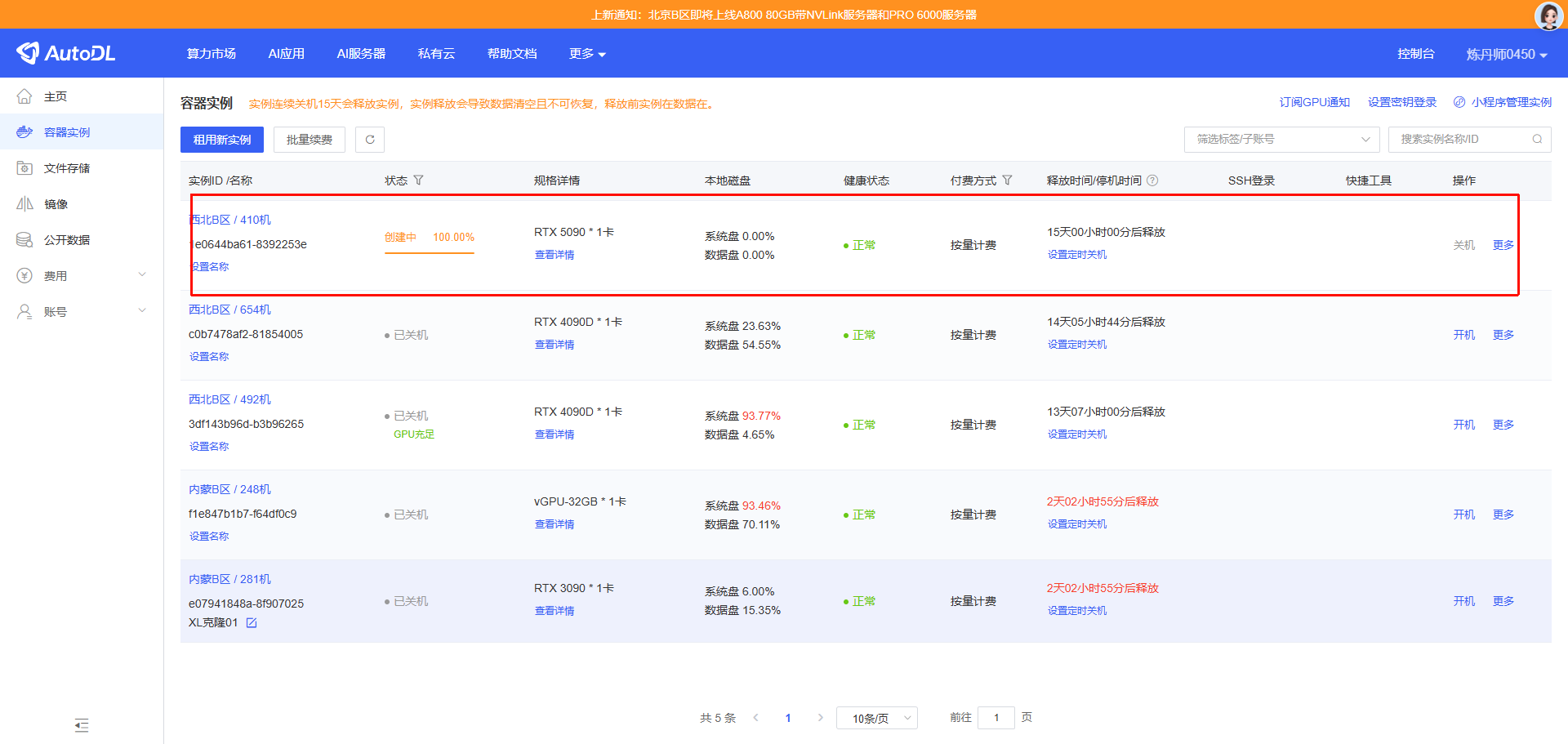
等待创建完成,此处约耗时3分钟。如果不在西北地区创建容器,此处的时间会更长约30分钟。
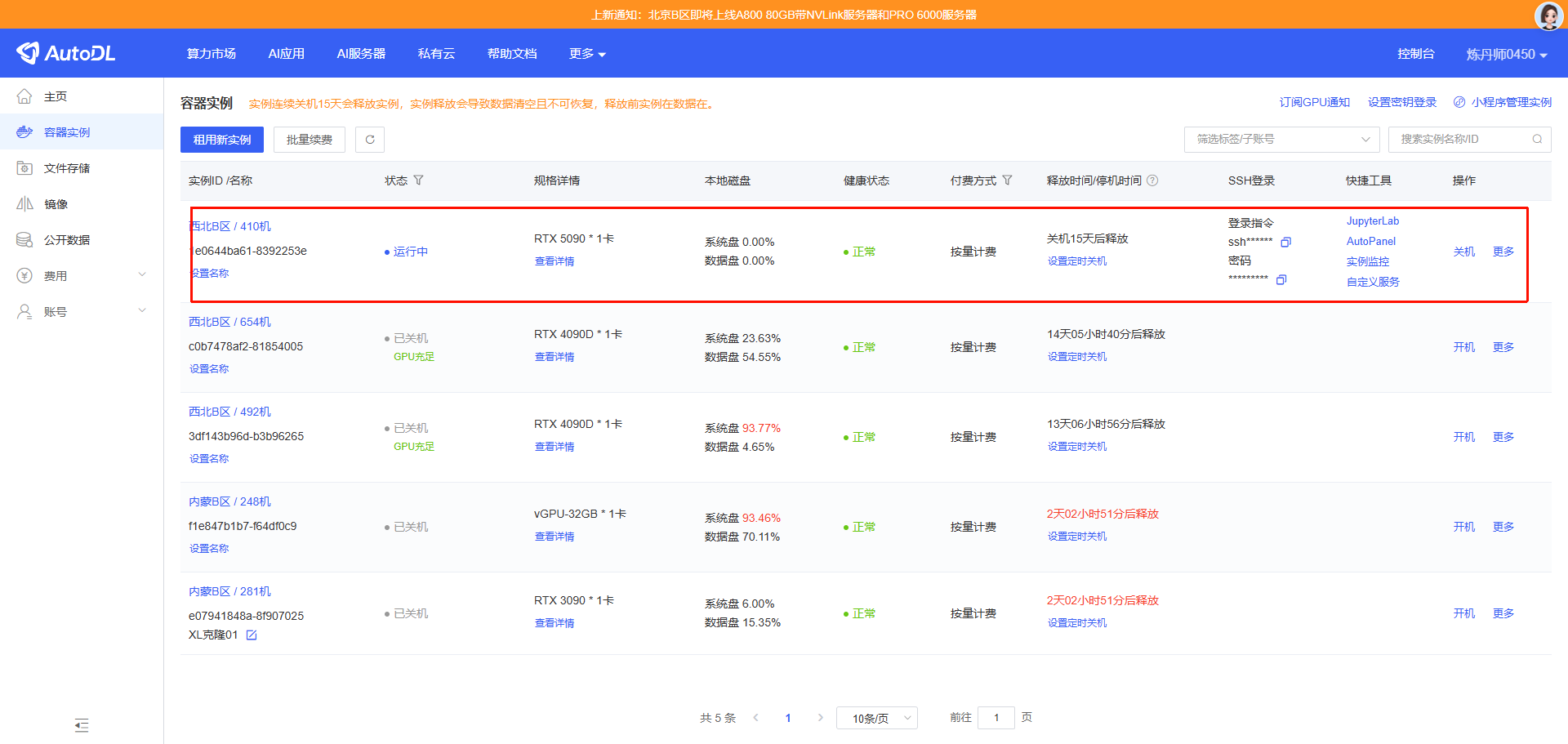
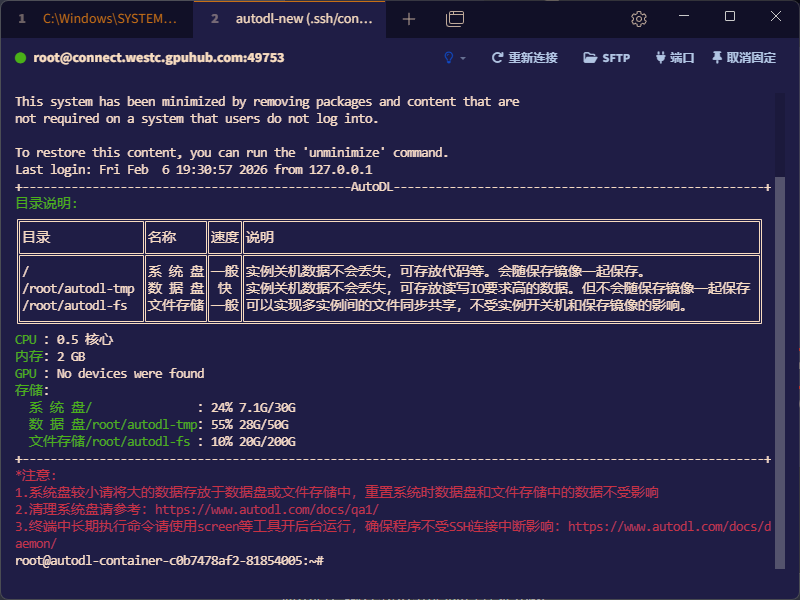
容器实例创建完成后会生成该实例的SSH登录指令和密码,我们可以通过SSH协议直接连接到对应的容器实例。

SSH远程登录
Tabby远程SSH登录
编辑ssh的config文件
windows电脑在:
C:\Users\<个人用户名>\.ssh目录下mac电脑在:
~/.ssh/config目录下,~表示为用户家目录。
根据容器SSH的登录命令不同,在config下新增以下内容:
例如,SSH登录命令为:ssh -p 39066 root@connect.westb.seetacloud.com
ssh -p 39066 root@connect.westb.seetacloud.com
新增内容为:
1 | Host autodl-new |
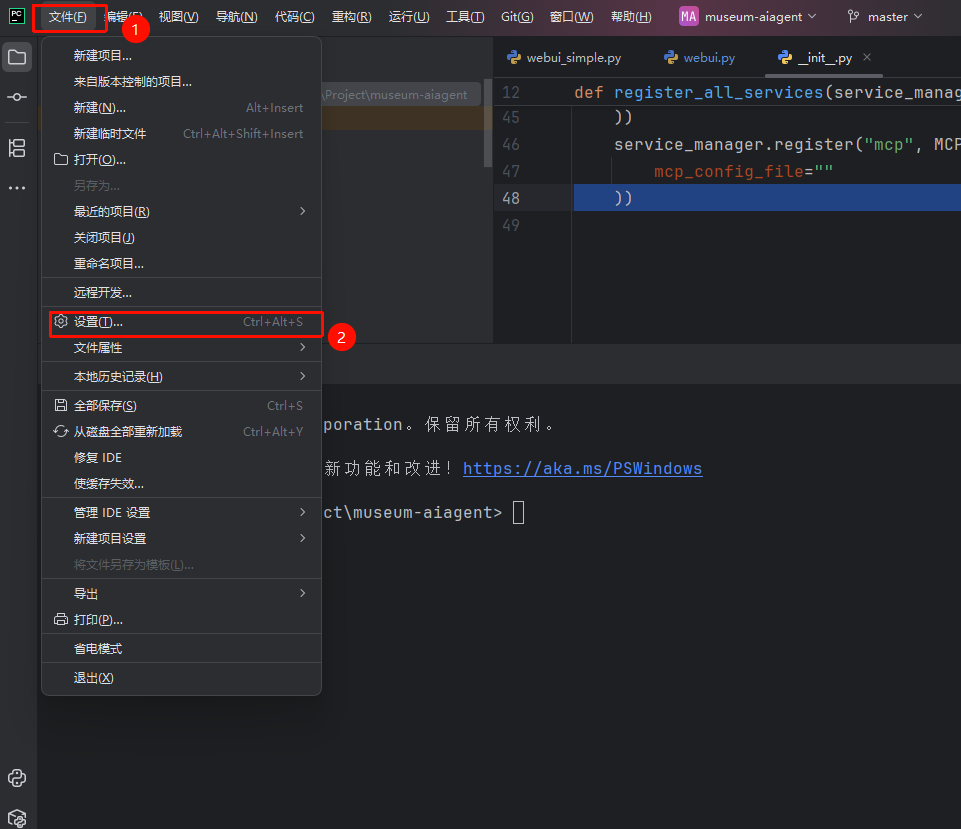
点击配置和连接
在弹窗中即可找到刚刚的配置项
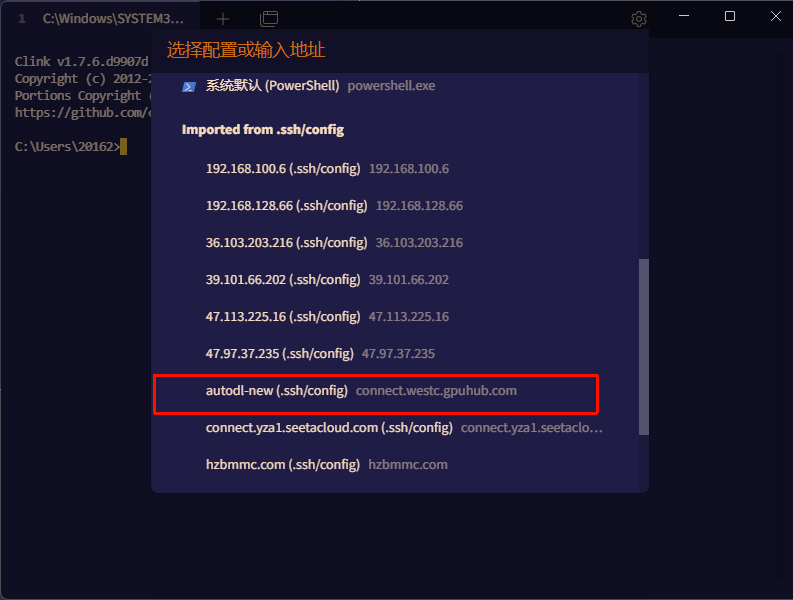
点击后,输入SSH密码即可登录完成
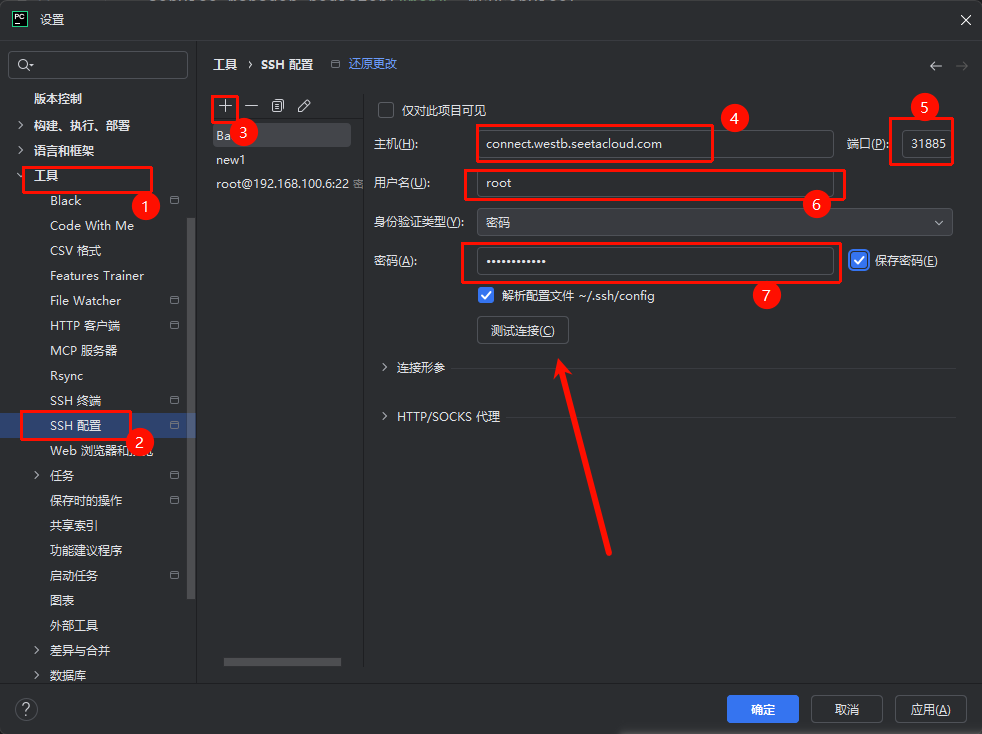
配置Pycharm远程SSH服务。
Pycharm专业版才有SSH配置功能,社区版无此功能。
主机相关信息可在容器实例列表获取
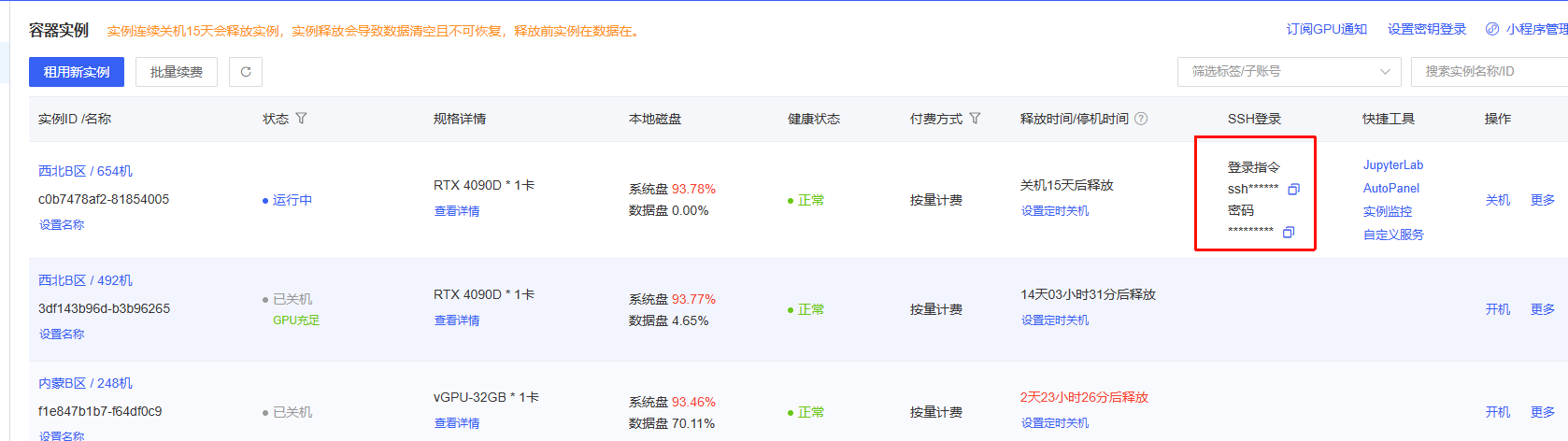
ssh -p 49753 root@connect.westc.gpuhub.com例如上面的SSH命令:
- 主机:
connect.westc.gpuhub.com- 端口:
49753- 用户名:
root- 密码直接在容器列表页复制即可。
配置完成后即可通过Pycharm进入到容器控制台
容器初始化
开启西北地区的文件存储
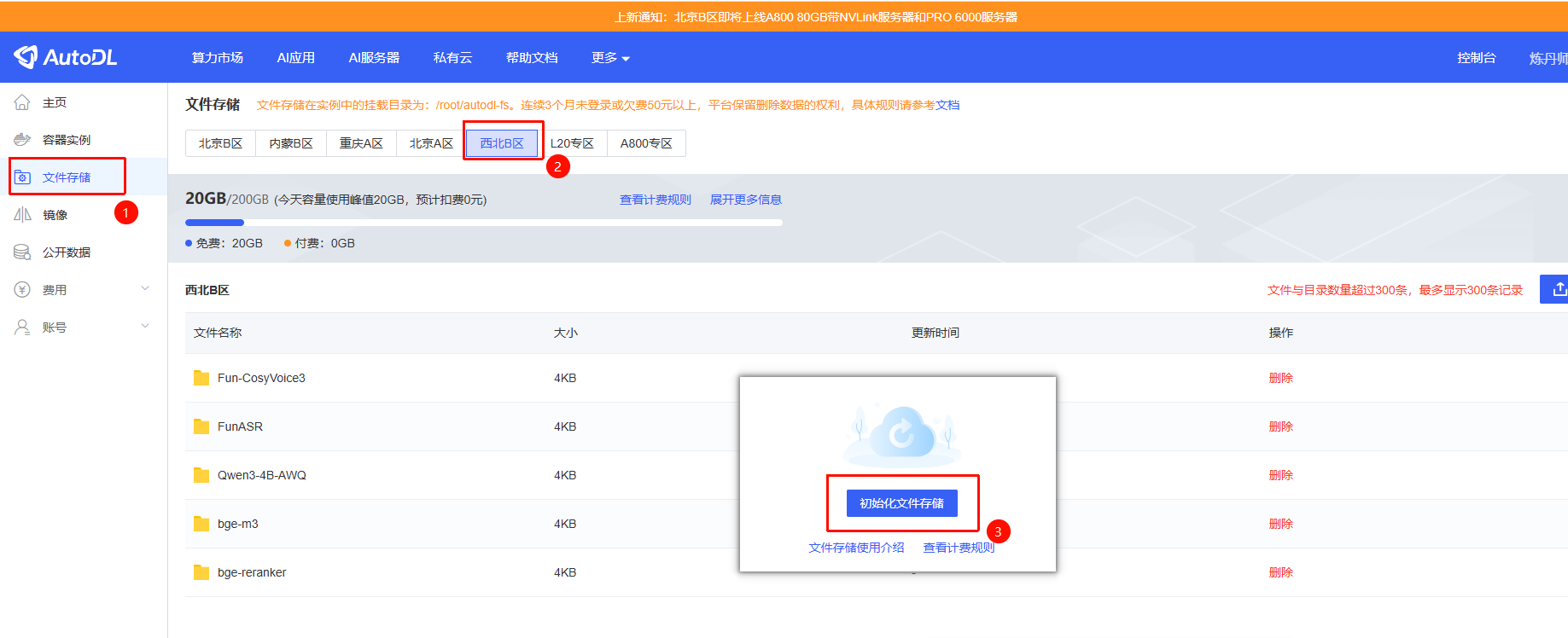
然后,进入终端,将模型文件移动到文件存储中,腾出系统盘空间,文件存储中的文件会共享到所有西北地区的容器中。
1 | cd && mv models/Fun-CosyVoice3 models/FunASR models/Qwen3-4B-AWQ models/bge* ~/autodl-fs |
移动完成后在AutoDL文件存储中即可看到对应文件
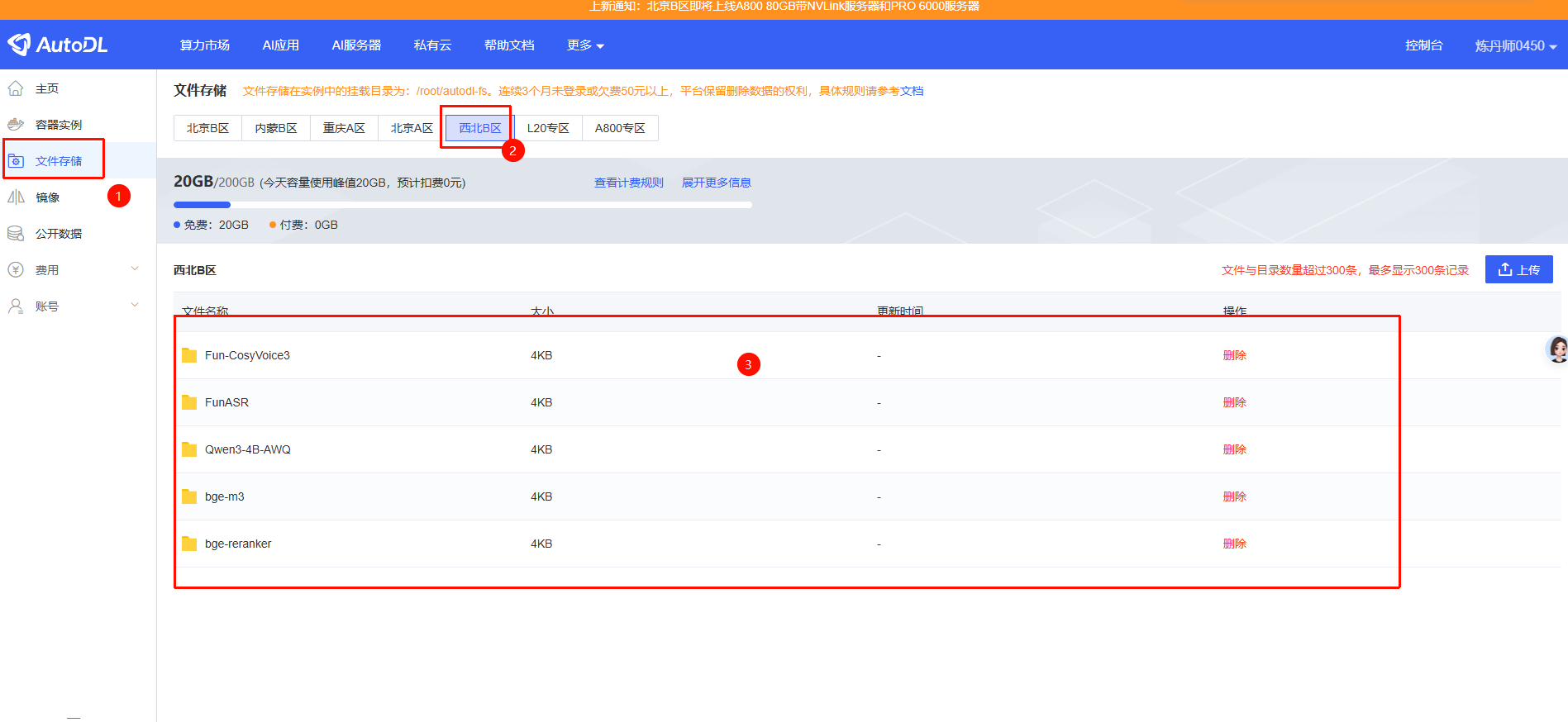
接下来将models文件夹中剩余的其他文件移动到autodl-tmp中
1 | cd && mv models/* ~/autodl-tmp |
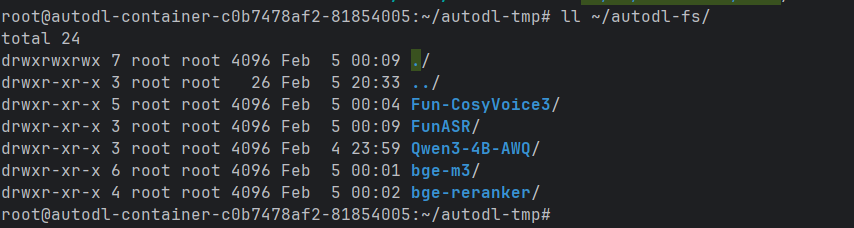
此时,autodl-fs文件夹下为
1 | ll ~/autodl-fs/ |
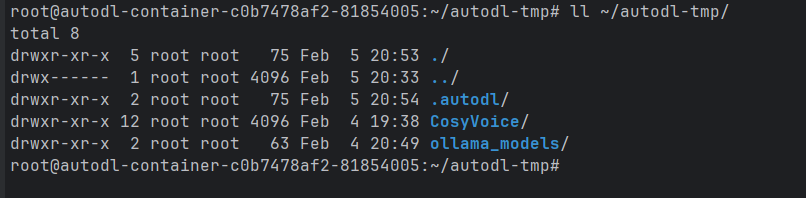
autodl-tmp文件夹下为
1 | ll ~/autodl-tmp/ |
Ollama框架介绍、安装与使用展示
Ollama介绍
Ollama 是一款开源的专为本地部署大型语言模型(LLM)而设计的轻量级推理引擎,旨在让用户能够在不依赖云计算资源的前提下,轻松地在个人电脑或服务器上运行如DeepSeek-R1、Qwen3等主流开源大模型。它以“本地部署、隐私保护、简洁易用”为核心理念,尤其适用于对数据安全有较高要求的开发者、科研人员及企业用户。
Ollama 的最大优势在于其极简的安装与使用方式。用户只需通过命令行输入 ollama run deepseek-r1 即可一键拉取并运行模型,省去了传统 LLM 环境配置中繁琐的依赖管理和编译过程。同时,它内置模型量化机制,大幅减少了对显存和计算资源的需求,使得主流模型能在消费级硬件(如笔记本电脑)上高效运行。
在数据隐私方面,Ollama 支持完全离线的本地推理流程。所有模型下载、加载与响应均在本地执行,无需将数据传输至云端,有效避免敏感信息泄露,特别适用于法律、医疗、金融等对隐私保护要求极高的行业场景。
Ollama安装部署与展示
【下列步骤可跳过,镜像已经将ollama安装好了】
接下来开始部署Ollama服务。
Ollama仓库地址:https://github.com/ollama/ollama ,在仓库中提供了详细的针对不同操作系统的安装教程,大家可以自行查看。在本教程中,主要介绍Ubuntu操作系统的安装。
首先,进入到/root/autodl-tmp目录,并开启学术加速
1 | cd /root/autodl-tmp && source /etc/network_turbo |
然后执行以下命令,下载ollama安装文件
1 | curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz |

注意,此处可能跟网速的快慢程度关联性比较大,下载速度有差异。
查看下载文件
1 | ll -lh ollama-linux-amd64.tgz |

可以看到文件已经下载成功,大小在1.3G左右。
解压并部署ollama
1 | sudo tar -C /usr -xzf ollama-linux-amd64.tgz |
这里大概会消耗3分钟左右的时间。
接下来编辑/root/.bashrc文件,设置ollama模型的存储目录和端口。
1 | export OLLAMA_HOST="0.0.0.0:6008" |

编辑时需要使用
vim命令,这个工具的用法可以去自行百度。
接下来,重新加载配置文件。(重启终端也可以)
1 | source /root/.bashrc |
ollama服务开启
开启ollama服务,查看服务是否正常
1 | ollama serve |

可以看到ollama服务成功开启在6008端口。
这个时候需要注意了,这个黑色窗口不能关闭,如果关闭了会导致ollama服务也会一起结束。但是,我们又不能一直把网站打开,我们希望服务部署好后,服务可以离线托管,这显然是不符合我们的项目需求的。要解决这个问题,就需要使用到tmux工具,这个工具可以做到离线托管终端代码。
下载tmux工具【可跳过,已经安装好了】
1 | apt install tmux |

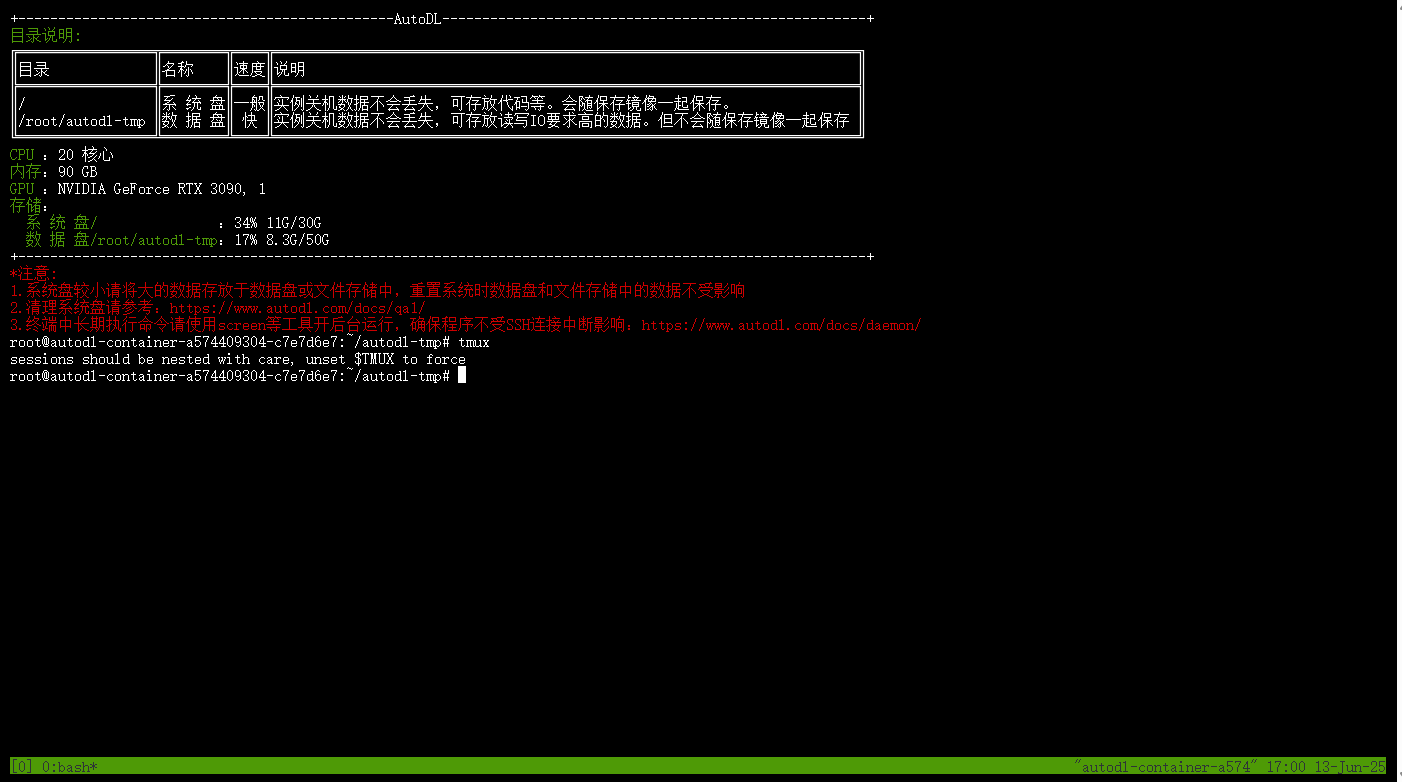
然后,直接在终端输入tmux,回车。该工具就会自动给我们创建一个可以用于离线托管的终端。
1 | tmux |
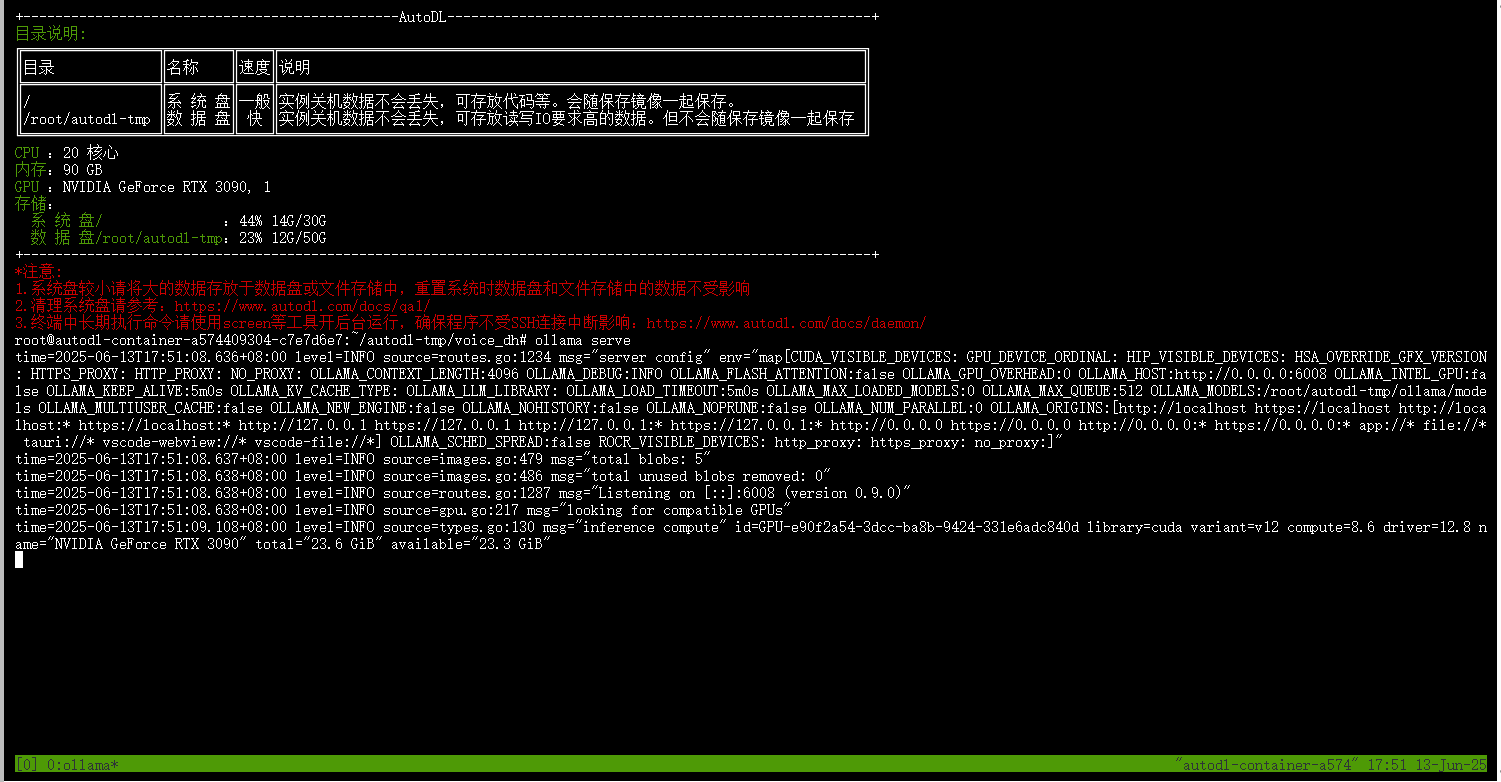
在该终端下,开启ollama服务。
1 | ollama server |
接下来就是关键的步骤,如何退出这个终端让终端在后台执行呢?
tmux工具提供了快捷命令,ctrl B+ d即可完成终端托管。

此时,终端会自动退回到我们之前使用的终端。
其他常用
tmux工具命令:我们可以通过以下命令,查看所有的后台终端
进入到某个后台终端
这个命令中的
0可以替换为其他终端的编号。

至此,Ollama部署完成
模型下载
Ollama支持大量开源大语言模型的部署与调用,并提供大预言模型不同参数量及不同量化版本的选择,我们可以根据自己的硬件水平和需求选择合适的模型进行部署使用。
ollama支持的模型可以在其官网查看:https://ollama.com/search

这里我们下载qwen3:4b模型
1 | ollama pull qwen3:4b |
如果超时,可以采用以下方式下载模型文件,然后再创建。
在
autodl-tmp目录下,创建虚拟环境
下载
modelscope【可跳过,镜像已经安装好了】
下载模型【可跳过,镜像已经下载好了】
创建
Modelfile文件【可跳过,镜像已经下载好了】
文件中填写以下内容
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
PARAMETER stop "<|im_start|>,<|im_end|>"
PARAMETER temperature 0.6
PARAMETER min_p 0.00
PARAMETER repeat_penalty 1.0
PARAMETER presence_penalty 1.5
PARAMETER top_k 20
PARAMETER top_p 0.95
PARAMETER num_predict 32768
PARAMETER num_ctx 40960
SYSTEM """
You are an AI developed by Alibaba Cloud. Your purpose is to assist users in finding information and answering their questions.
"""
TEMPLATE """
{{ if .System }}
<|im_start|>system
{{ .System }}
<|im_end|>
{{ end }}
{{ if .Prompt }}
<|im_start|>user
{{ .Prompt }}
<|im_end|>
{{ end }}
<|im_start|>assistant
{{ .Response }}
<|im_end|>
"""创建模型
使用
ollama运行模型

通过接口进行进阶使用
ollama部署完成后,我们除了可以直接在终端中进行使用和对话之外,ollama还给我们提供了接口,我们也可以通过接口的方式进行使用。
ollama接口官方文档:https://github.com/ollama/ollama/blob/main/docs/api.md
常用接口及其功能:
| 接口路由 | 请求方式 | 接口功能 |
|---|---|---|
/api/generate |
POST | 生成一问一答(无法保存对话历史) |
/api/chat |
POST | 生成多轮对话结果(可保存对话历史) |
/api/tags |
GET | 查看所有的本地模型 |
/api/pull |
POST | 从ollama库中下载模型 |
/api/embed |
POST | 从模型生成嵌入向量 |
🚀generate
请求参数:
model:必填项,模型名称。system:系统提示词。prompt:用于生成回复的提示词。stream:是否进行流式传输。options:模型文件文档中列出的其他模型参数,例如:num_ctx(max_tokens)、temperature、top_p等等。images:可选项,一个经过Base64编码的图像列表(适用于像llava这样的多模态模型)。think:(针对思考型模型)模型在回复前是否应该进行思考?
响应参数:
total_duration:生成回复所花费的时间load_duration:加载模型所花费的时间(单位:纳秒)prompt_eval_count:提示词中的词元数量prompt_eval_duration:评估提示所花费的时间(以纳秒为单位)eval_count:响应中的词元数量eval_duration:生成回复所花费的时间(单位:纳秒)context:本次回复中使用的对话编码,可在下次请求中发送,以保留对话记忆response:如果响应是流式传输的,则为空;如果不是流式传输的,则此内容将包含完整的响应。
使用POSTMAN进行接口测试:
非流式

流式

使用Python代码进行接口测试
1 | import requests |
🚀chat
请求参数:
model:必填项,模型名称。messages:聊天的消息,可用于保存聊天记录。stream:是否进行流式传输。options:模型文件文档中列出的其他模型参数,例如:num_ctx(max_tokens)、temperature、top_p等等。images:可选项,一个经过Base64编码的图像列表(适用于像llava这样的多模态模型)。tools:如果模型支持,可供其使用的工具列表,以JSON格式呈现think:(针对思考型模型)模型在回复前是否应该进行思考?
响应参数:
total_duration:生成回复所花费的时间load_duration:加载模型所花费的时间(单位:纳秒)prompt_eval_count:提示词中的词元数量prompt_eval_duration:评估提示所花费的时间(以纳秒为单位)eval_count:响应中的词元数量。eval_duration:生成回复所花费的时间(单位:纳秒)context:本次回复中使用的对话编码,可在下次请求中发送,以保留对话记忆message:返回的结果,以字典的形式返回,和请求中的messages中元素的结构一致。
使用POSTMAN进行接口测试
非流式

流式

使用Python代码进行接口测试
1 | import requests |
注意:
generate接口和chat接口的解析方式不一样,需要修改。
🚀embed
这个是Ollama中的Embedding模型接口,用于将自然语言转化为嵌入向量。
要测试这个接口需要在ollama中下载一个embed模型,在官网(https://ollama.com/search)中点击页面中的`Embedding`即可进行筛选。

比如,在这里我们下载nomic-embed-text,在终端中输入以下命令。
1 | ollama pull nomic-embed-text |

Embedding一般较小,下载速度很快。下载完成后,接下来进行接口测试。
使用POSTMAN进行接口测试

使用Python代码进行接口测试
1 | import requests |
其他接口比较简单,大家可以自行测试,在此处不过多赘述。
代码已经开源到以下仓库:https://gitee.com/ming_log/ollama_api_request