相关服务部署
FunASR部署
项目地址:https://github.com/modelscope/FunASR
下载模型【已下载】
1 | modelscope download iic/SenseVoiceSmall --local_dir /root/autodl-fs/FunASR/SenseVoiceSmall |
创建虚拟环境
1 | mkdir ~/autodl-tmp/FunASR && cd ~/autodl-tmp/FunASR |
安装依赖
1 | source .venv/bin/activate |
安装 torch环境
1 | uv pip install torch torchvision torchaudio --index-url https://mirrors.nju.edu.cn/pytorch/whl/cu126 |
安装ffmpeg
1 | apt install ffmpeg -y |
测试环境是否可用
下载测试音频
1 | cd ~/autodl-tmp/FunASR |
1 | wget https://shuming-ai-pic.oss-cn-hangzhou.aliyuncs.com/20260127_205117_64624e1eae.mp3 |
新建测试代码
1 | vim test.py |
编辑步骤:
- 先按
i进入编辑模式 - 复制内容
- 按
ESC退出编辑模式 :wq+回车
复制以下内容
1 | from funasr import AutoModel |
执行脚本
1 | source .venv/bin/activate && python test.py |

TTS部署
EdgeTTS部署
创建项目目录
1 | cd /root/autodl-tmp && mkdir EdgeTTS && cd EdgeTTS |
创建虚拟环境
1 | cd /root/autodl-tmp/EdgeTTS && uv venv --python 3.12 |
安装依赖
1 | source .venv/bin/activate && uv pip install edge-tts -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com |
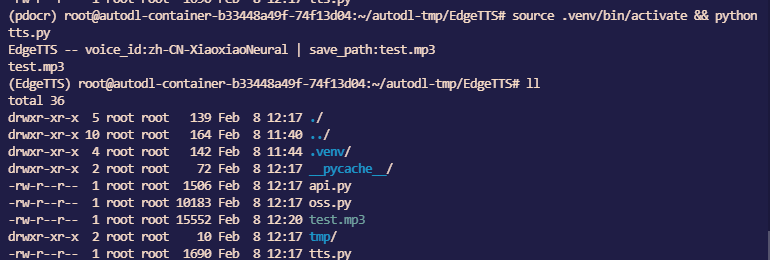
编辑tts.py文件,文件内容如下所示:
1 | import asyncio |
执行测试脚本
1 | source .venv/bin/activate && python tts.py |
CosyVoice3.0部署【环境有问题可换用EdgeTTS】
项目地址:https://github.com/FunAudioLLM/CosyVoice
下载模型【已下载】
1 | modelscope download FunAudioLLM/Fun-CosyVoice3-0.5B-2512 --local_dir /root/autodl-fs/Fun-CosyVoice3 |
克隆 CosyVoice项目【已克隆】
1 | cd ~/autodl-tmp/CosyVoice |
项目如果未克隆,则使用以下命令进行克隆。
创建虚拟环境并激活【已创建】
1 | source .venv/bin/activate |
如果未创建,使用以下命令
2
source .venv/bin/activate
下载依赖
1 | pip cache purge |
1 | source .venv/bin/activate && uv pip install protobuf==4.25.0 tokenizers==0.21.4 networkx sympy pillow triton -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com |
1 | uv pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com |
安装 vllm环境
1 | uv pip install vllm==0.9.0 transformers==4.51.3 numpy==1.26.4 -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com |
更新 PyYAML、hyperpyyaml。
1 | uv pip install --upgrade PyYAML hyperpyyaml -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com |
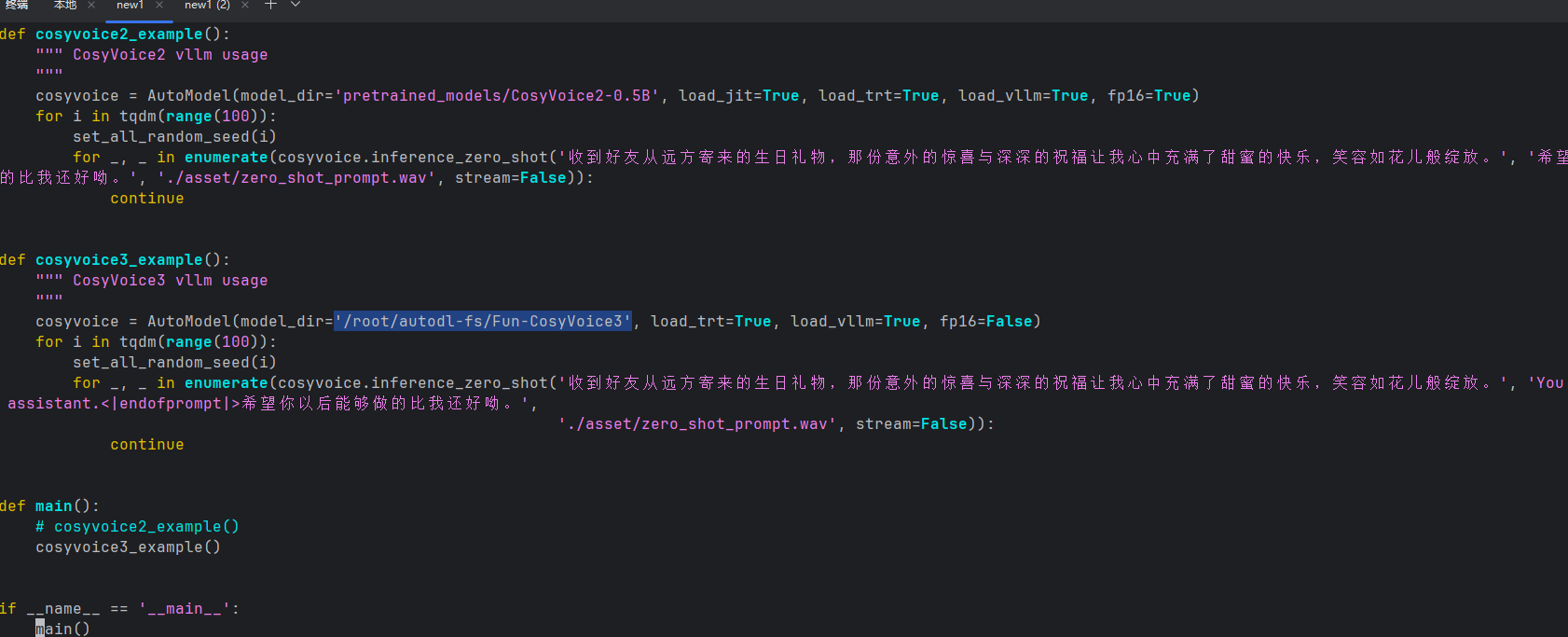
修改测试脚本中模型路径
1 | vim vllm_example.py |
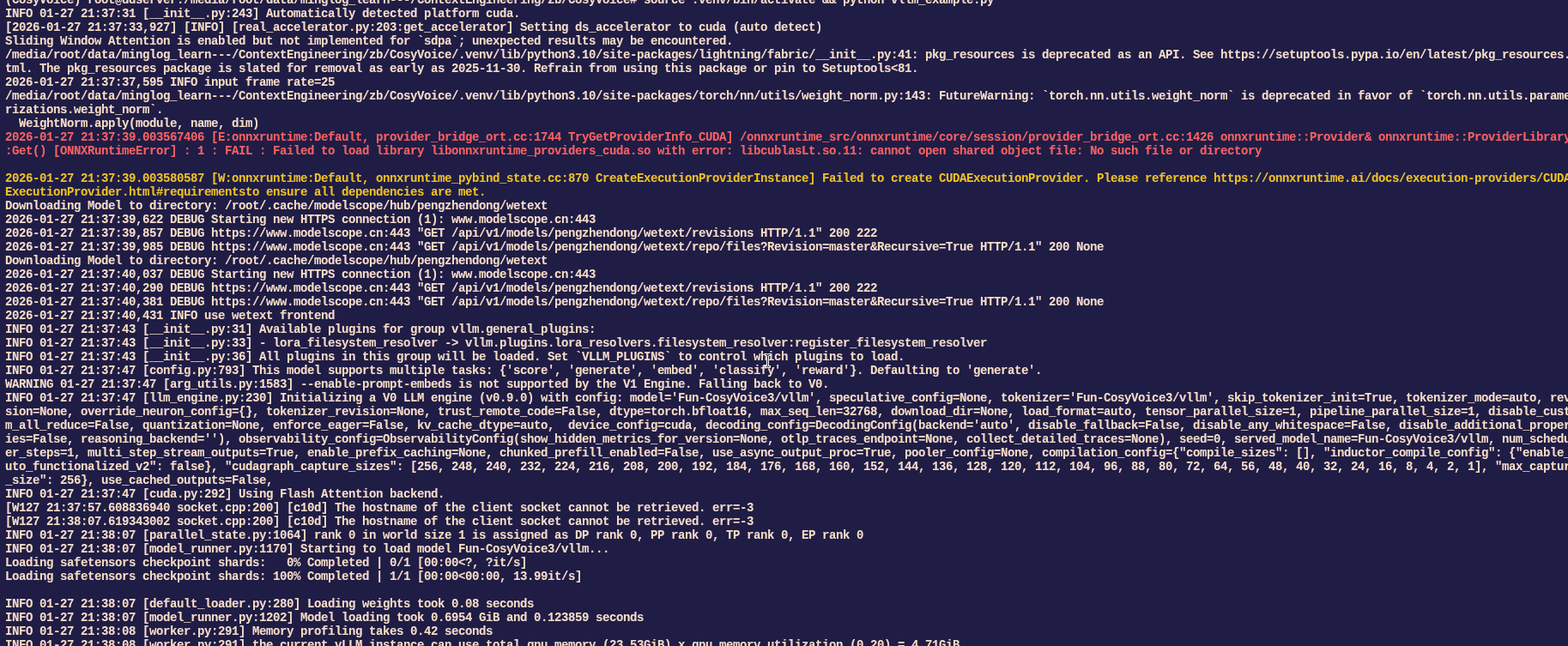
激活虚拟环境,执行测试脚本
1 | source .venv/bin/activate && python vllm_example.py |

PaddleOCR部署
项目地址:https://github.com/PaddlePaddle/PaddleOCR
创建项目目录
1 | cd ~/autodl-tmp && mkdir pdocr && cd pdocr |
创建虚拟环境
1 | uv init && uv venv --python 3.12 |
安装 paddlepaddle环境
1 | source .venv/bin/activate && uv pip install paddlepaddle-gpu==3.3.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/ --index-strategy unsafe-best-match |
安装 paddleocr
1 | uv pip install paddleocr -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com |
下载测试图片
1 | wget https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png -O img.png |
识别测试图片:

1 | paddleocr ocr -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png --use_doc_orientation_classify False --use_doc_unwarping False --use_textline_orientation False |
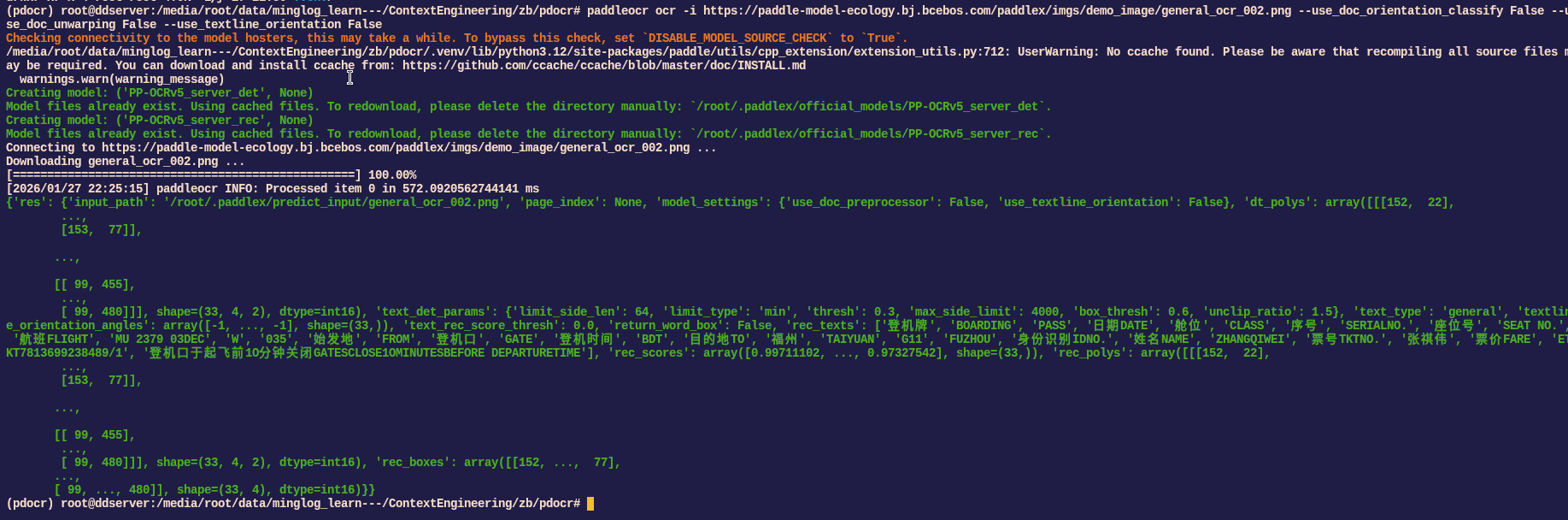
编写脚本测试:
1 | vim test.py |
复制以下代码:
1 | from paddleocr import PaddleOCR |
执行脚本:
1 | source .venv/bin/activate && python test.py |
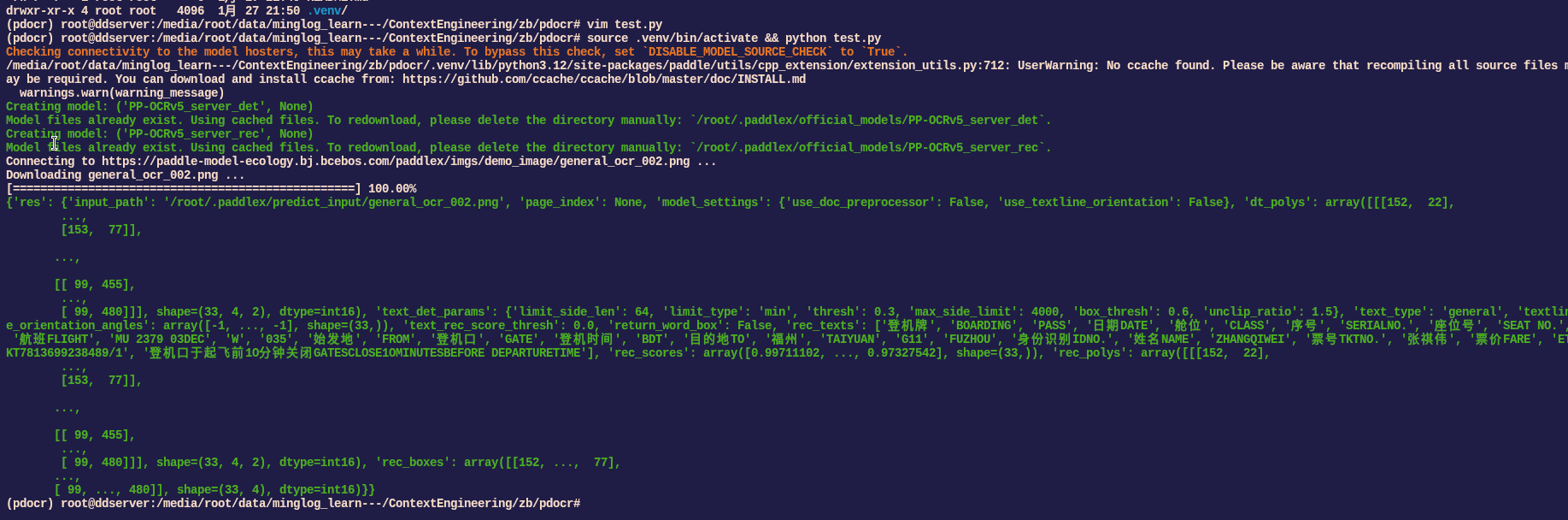
识别结果:

接口封装
ASR接口封装
下载接口依赖
1 | cd /root/autodl-tmp/FunASR && source .venv/bin/activate && uv pip install fastapi httpx uvicorn -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com |
然后在项目中新建文件 api.py,填入以下内容:
1 | vim api.py |
1 | import os, httpx, logging |
启动后端接口服务:
1 | python api.py |
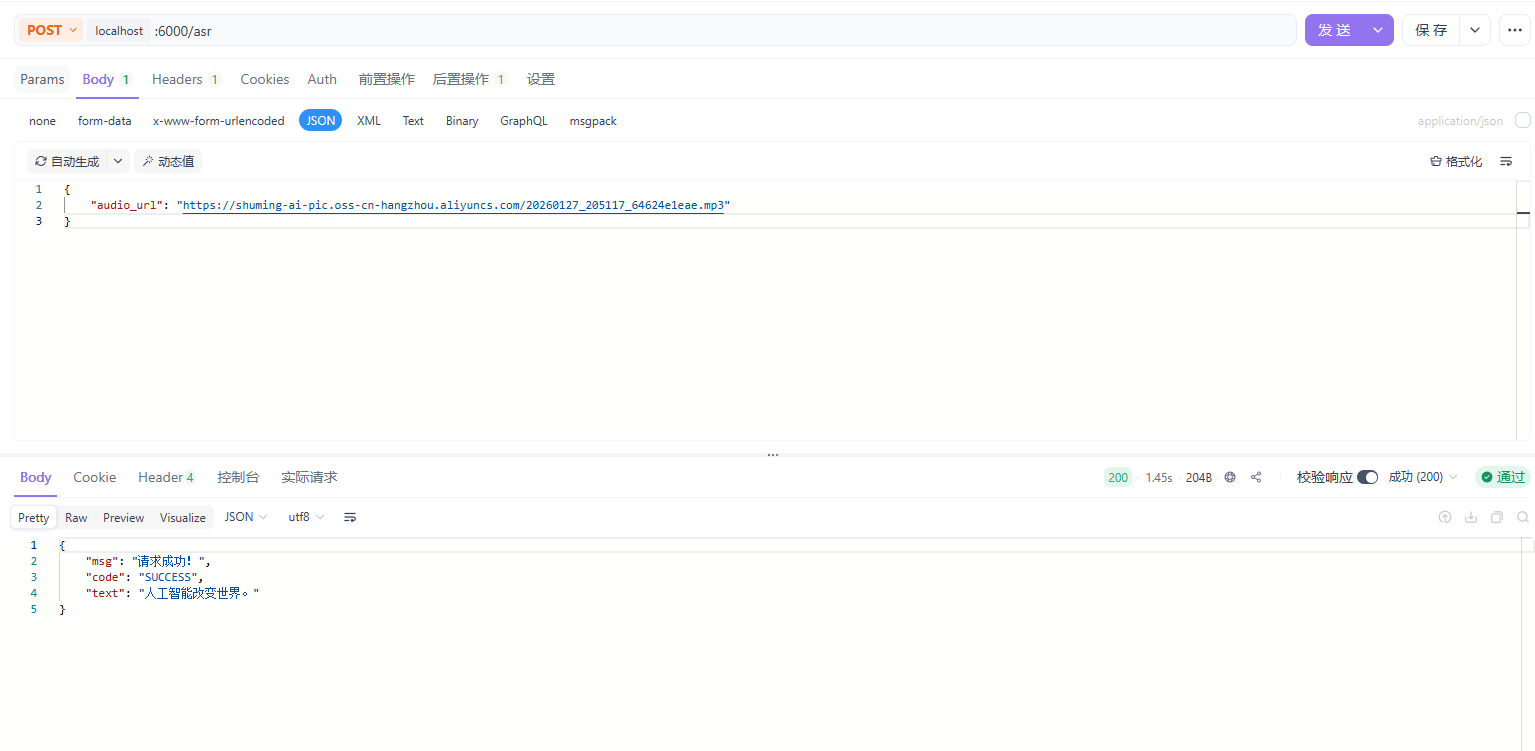
使用 POSTMAN测试接口
请求地址:localhost:6000/asr
请求方法:POST
请求体:
1 | { |
响应示例:
TTS接口封装
Edge-TTS接口
下载接口依赖
1 | cd /root/autodl-tmp/EdgeTTS && source .venv/bin/activate && uv pip install fastapi minio uvicorn -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com |
然后在项目中新建文件 api.py,填入以下内容:
1 | from datetime import datetime |
开启接口服务
1 | python api.py |
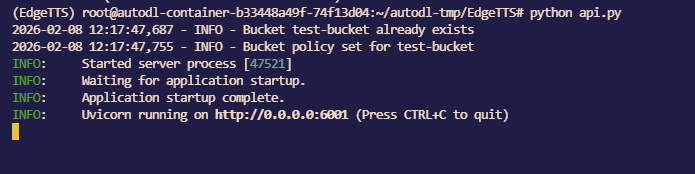
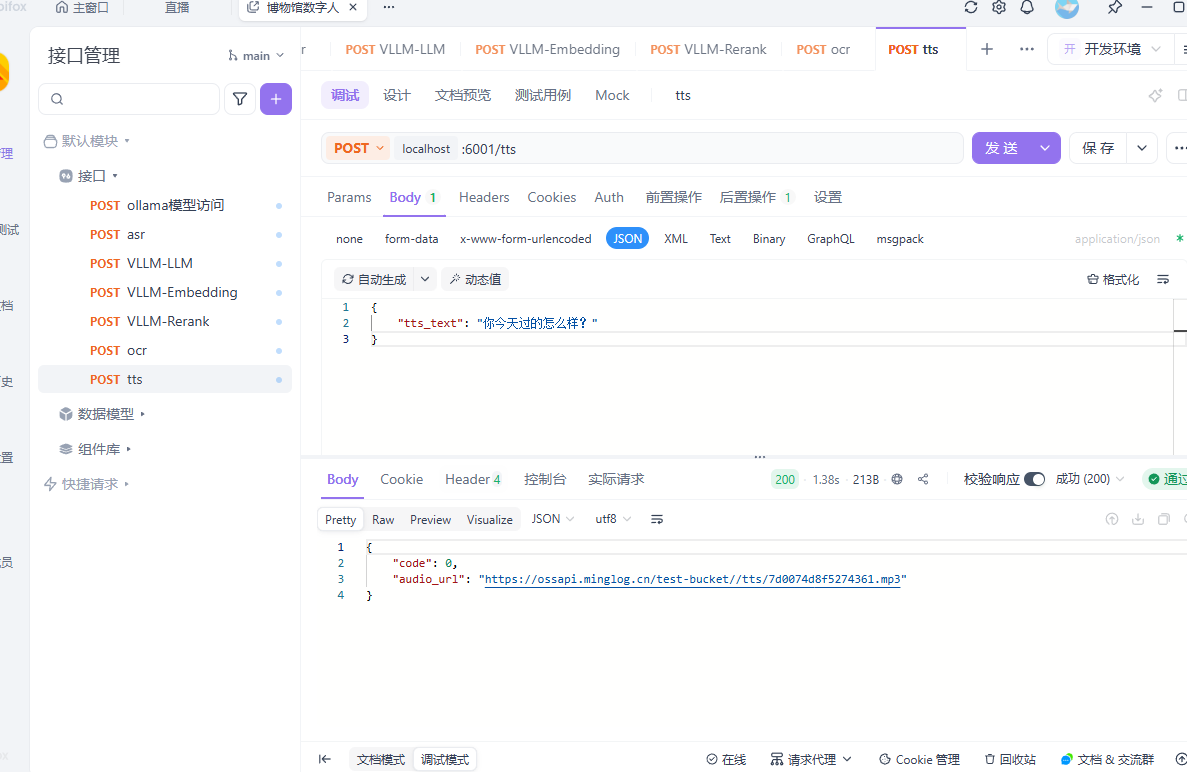
使用 POSTMAN测试接口
请求地址:localhost:6001/tts
请求方法:POST
请求体:
1 | { |
响应示例:
CosyVoice接口
下载接口依赖
1 | cd /root/autodl-tmp/CosyVoice && source .venv/bin/activate && uv pip install fastapi httpx uvicorn minio -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com |
然后在项目中新建文件 api.py,填入以下内容:
1 | import sys |
启动后端接口服务:
1 | python api.py |
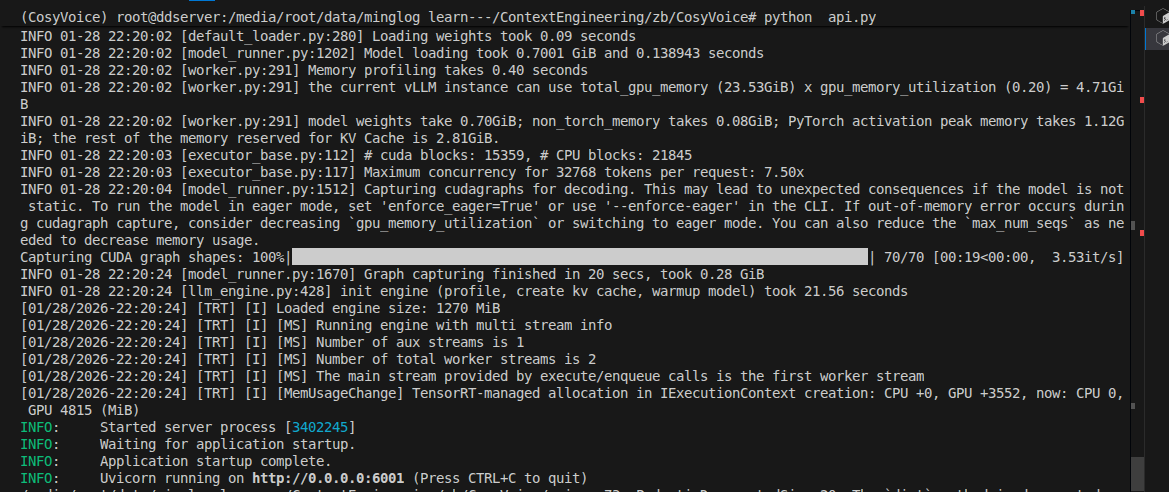
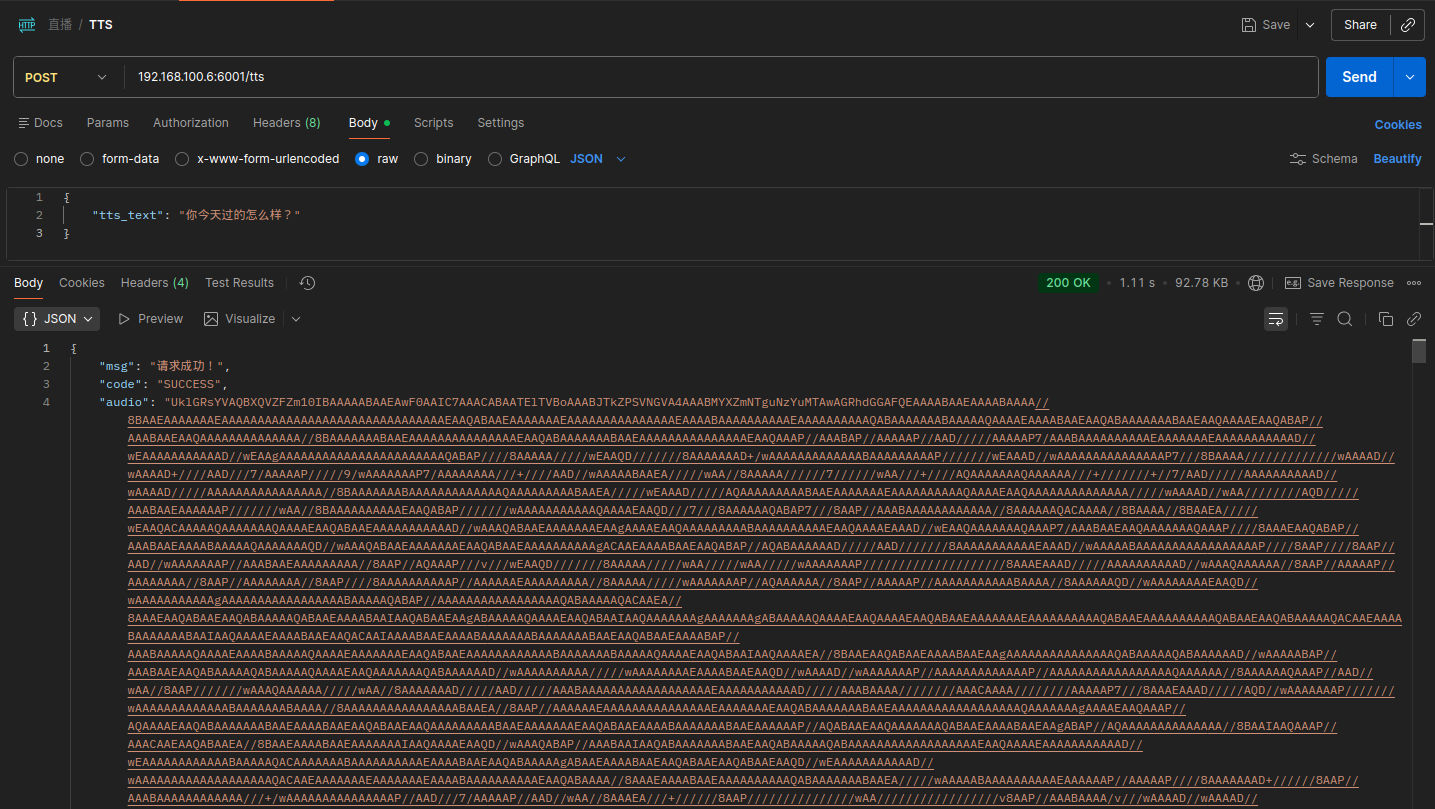
使用 POSTMAN测试接口
请求地址:localhost:6001/tts
请求方法:POST
请求体:
1 | { |
响应示例:
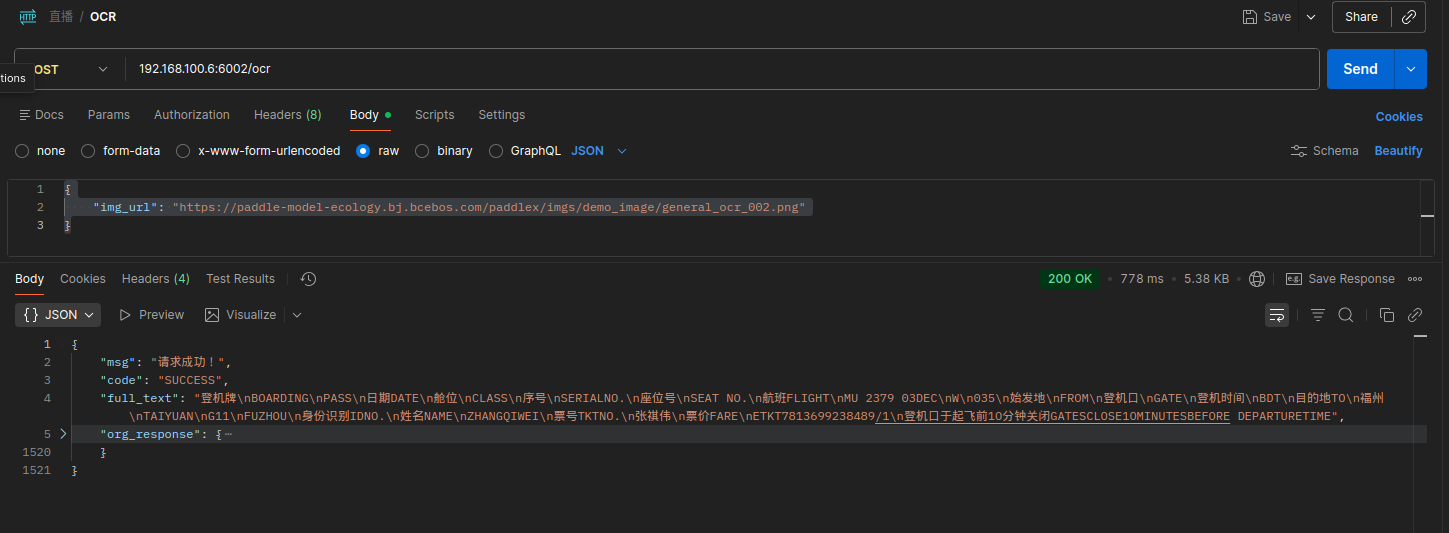
OCR接口封装
下载接口依赖
1 | cd ~/autodl-tmp/pdocr && source .venv/bin/activate && uv pip install fastapi httpx uvicorn -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com |
然后在项目中新建文件 api.py,填入以下内容:
1 | import os, httpx, logging |
使用 POSTMAN测试接口
请求地址:localhost:6002/ocr
请求方法:POST
请求体:
1 | { |
响应示例: